Making Your Data Hot: Heatmaps for the Display of Large Tables
Don’t forget that you can easily use Displayr’s heatmap maker to create your free heatmap!
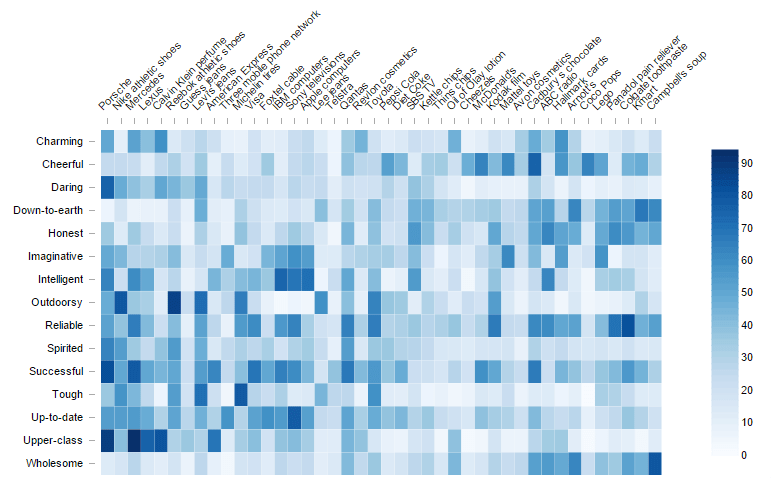
Sometimes tables are just too big to read. The table below shows the personality attributes that people associate with different iconic brands. A table too big to read easily and too big to show elegantly on a web page, in this case, leaves only the first page visible. A heatmap, which replaces the numbers with colors or shades proportional to the numbers in the cell, is a lot easier for our brains to digest.
While we were unable to display all the data in the table above, the heatmap below shows it all nicely. By replacing the numbers with colors, all 42 columns and 15 rows fit in one compact view.
An additional benefit of the visualization is that it is an image. With a table, our brains need time to process each of the numbers and work out their implications. A heatmap, on the other hand, allows our brains to readily detect the differences in intensity. You can still view the numbers in these examples by hovering your mouse over the heatmap.
Making patterns in heatmaps easier to spot
While we can hunt out patterns in this heatmap, it is a painful process. Reducing the size of the visualization makes patterns easier to see. They are not, however, simplified. A common solution to this problem applies both here and to tables: compute the average of each row and column, and sort the table from highest to lowest (see below).
We can see from this that the personality traits that are near-synonyms for appeal are at the top, indicating they were most likely to be associated with these brands (all of which are successful). We can also see that the car brands appear mainly on the left. This highlights that years of personality-based car advertising has had some effect.
Using cluster analysis to improve the heatmap
While reordering of the rows and columns has improved the visualization, it has not highlighted patterns showing the relationship between the personality attributes and the brands, which is the main goal of the analysis. We can improve the heatmap further, by clustering rows and columns so as to group together similar rows and columns. The visualization below has dendrograms showing these groupings. The visualization is now, at last, paying off in terms of allowing us to see interesting conclusions.
To name two:
• On the left, we can see a cluster of luxury brands, starting with Calvin Klein through to Porsche.
• The next set of brands contains more rugged outdoorsy brands, including jeans, shoes, and just one car brand: Toyota. There of course many more insights that now leap from the visualization.
TRY IT OUT
You can play with the R code used to create these examples in Displayr.
Acknowledgements
Thanks go to Michael Bostock, Joe Cheng, Tal Galili, and Justin Palmer, who did the heavy lifting in creating the wonderful d3heatmap package used in this blogpost, and to Michael Wang who tweaked it so it did precisely what I wanted.