

What is penalty analysis?
Penalty analysis is a tool used to work out which attributes of a product have the greatest effect on how much people like it. For example, if our product is a chocolate cookie, which of these attributes – crunchiness, flavor, or coating effect – have the biggest impact on how much people like the cookie?
Respondents are asked to rate how much they like the product, often on a 9-point scale. Then, respondents are asked about a set of specific attributes of the product and asked to rate them on the basis of ‘too much’, ‘just about right’, or ‘not enough’. As usual, these scales vary.
Penalty analysis calculations take this data and aims to work out which of the attributes cause the biggest drop-offs in how much people like the product when an attribute is “too much” or “not enough”. This is called the ‘penalty’. In this post I’ll show you how to do some common penalty analysis calculations in Displayr using R.
1. Prepare your data
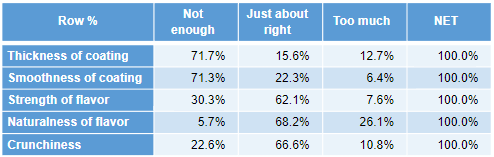
The variables for your just-about-right scale (JAR) must be combined as a Variable Set with the Structure of Grid with mutually exclusive categories (Nominal – Multi). For this particular calculation you need to group the scale as three categories. The order of the categories must be “Not enough” on the left, followed by “Just about right”, followed by “Too much”. The resulting table should look like the one below.
If you have not combined your variables, follow these steps:
- Select the variables in the Data Sets tree in the bottom left pane (select the variables by holding down your CTRL key).
- From the Data Manipulation > Variables menu, click Combine.
- Right-click on the combined variables in the Data Sets tree, select Rename and enter an appropriate name.
- From the Object Inspector in the right pane, change the Structure drop-down box to Grid with mutually exclusive categories (Nominal – Multi).
If your scale has more than three categories you may need to group them together:
- Highlight the column labels to group.
- From the Data Manipulation > Rows/Columns menu, click Merge.
- Again from the Data Manipulation > Rows/Columns menu, click Rename and enter a new column name.
Set the “liking” scale as a Number question. Your table should look like the one below:

If you need to change the Structure, find the question in the Date Sets tree and from the Object Inspector, change the Structure in the INPUTS section to Numeric.
2. Create your ‘Just-About-Right’ table
You can create all the statistics you need to compute the penalties by following these steps:
- Create a new table by dragging the “JAR Distribution” question onto the page.
- With the table selected, go to the Object Inspector and select the “Liking Score” from the By drop-down box.
- From the Object Inspector, select the Cells drop-down box in the STATISTICS section and ensure that the Average and Weighted Row Sample Size statistics are selected.
Your table should look like this:
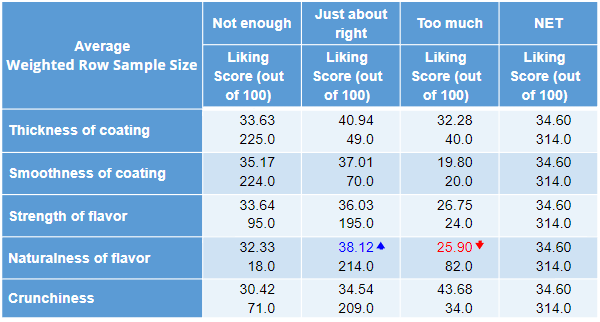
The Averages show the average liking score among people who consider each attribute “Not enough”, “Just about right”, and “Too much”. The Weighted Row Sample Size shows the weighted sample size for each of these groups.
Finally, to make the calculations easier:
- Click on the Properties tab in the Object Inspector and right-click the name.
- In the GENERAL section, change the Name of the object to jar.scores.
This determines how we can refer to this table of results when doing calculations in R.
3. Calculate the total penalty
Calculate the penalty by working out how much the average liking score drops between “Just about right” and “Not enough”, and between “Just about right” and “Too much”. These drops are weighted by the proportion of respondents in the “Not enough” and “Too much” categories and then added together to give the total penalty for each attribute.
To compute the total penalties we can use a little R code:
- Select Insert > R Output (Analysis)
- Paste in the code below.
- Click Calculate.
The code for the penalty is as follows:
input.table = jar.scores
scores = input.table[,1:3,1,1] # Get the average scores
pops = input.table[,1:3,1,2] # Get the weighted sample sizes
sum.pops = rowSums(pops) # Compute the total sample for each row
# Work out the drops in average score between just-about-right and too much
# and just-about-right and not enough for each row. Values less than zero
# are set to zero
diff.low = rep(0, nrow(scores))
diff.high = rep(0, nrow(scores))
for (row in 1:nrow(scores)) {
diff.low[row] = max(scores[row, 2] - scores[row,1], 0)
diff.high[row] = max(scores[row, 2] - scores[row, 3], 0)
}
# Compute the proportion of the sample in the "not enough"
# and "too much" group for each row
prop.low = pops[, 1] / sum.pops
prop.high = pops[, 3] / sum.pops
# Compute the penalties, weighted by proportions
penalty.low = prop.low*diff.low
penalty.high = prop.high*diff.high
# compute the total penalty
total.penalty = penalty.low + penalty.high
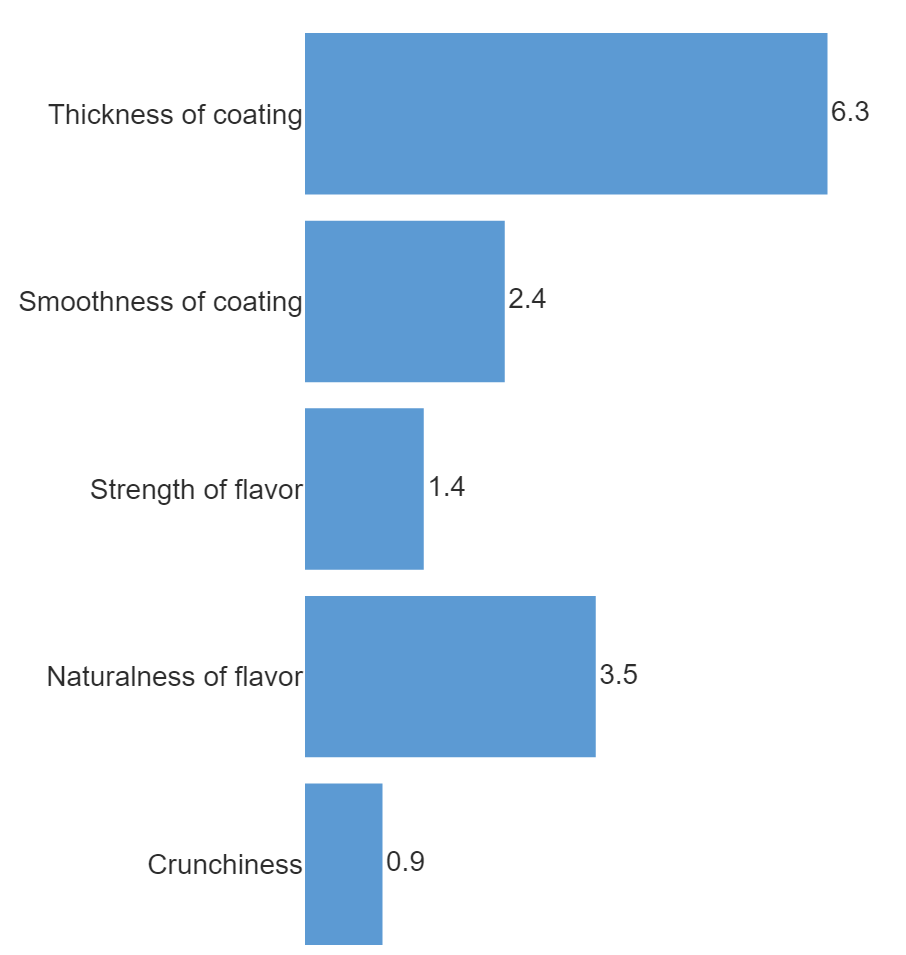
This will produce a table like the following, showing which attributes have the biggest penalty.

To make a visualization of this:
- Select Insert > More (Analysis) > Visualization > Bar Chart.
- From DATA SOURCE section in the Object Inspector, select the table (called total.penalty) from the Output in ‘Pages’ drop-down box.
- Select formatting options in the Chart section of the options on the right.
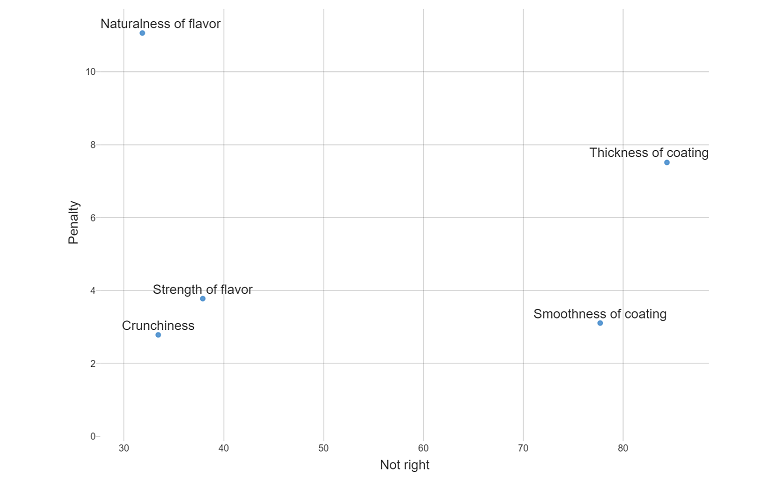
4. Chart penalty vs % of consumers
It is also important to consider the penalties in comparison to the proportion of the sample who regard the product as being “not right” according to each attribute. This is the percentage of people who rated each attribute as either “too much” or “not enough”.
For this calculation we scale each penalty by the proportion of people who rated that attribute as “not right”, and we plot this weighted penalty against that percentage.
To work out the proportion of respondents who rated each attribute as “not right” and calculate the weighted penalties:
- Select Insert > R Output (Analysis).
- Enter the code below.
- Click Calculate.
input.table = jar.scores
scores = input.table[,1:3,1,1] # Get the average scores
pops = input.table[,1:3,1,2] # Get the weighted sample sizes
sum.pops = rowSums(pops) # Compute the total sample for each row
# Work out the drops in average score between just-about-right and too much
# and just-about-right and not enough for each row. Values less than zero
# are set to zero
diff.low = rep(0, nrow(scores))
diff.high = rep(0, nrow(scores))
for (row in 1:nrow(scores)) {
diff.low[row] = max(scores[row, 2] - scores[row,1], 0)
diff.high[row] = max(scores[row, 2] - scores[row, 3], 0)
}
# Compute the proportion of the sample in the not enough
# and too much group for each row
prop.low = pops[, 1] / sum.pops
prop.high = pops[, 3] / sum.pops
# Compute the penalties, weighted by proportions
penalty.low = prop.low*diff.low
penalty.high = prop.high*diff.high
# compute the total penalty
total.penalty = penalty.low + penalty.high
# work out the percentage of people in either too much or not enough
not.right = prop.high + prop.low
# Scale each penalty by the proportion of respondents who rated that category
# too much or not enough
weighted.penalty = total.penalty / not.right
# Combine the two together
penalty.not.right = cbind("Not right" = not.right * 100, "Penalty" = weighted.penalty)
The resulting table will look like this:
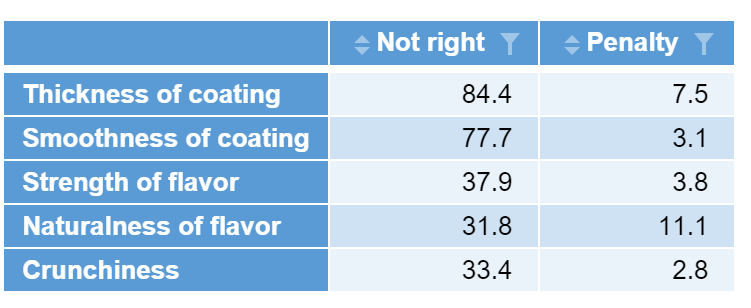
To visualize the results:
- Select Insert > More (Analysis) > Visualization > Scatterplot.
- Select the table (called penalty.not.right) from the Output in ‘Pages’ drop-down box in the Object Inspector.
- From the Chart section, select On chart from the Show labels drop-down box.
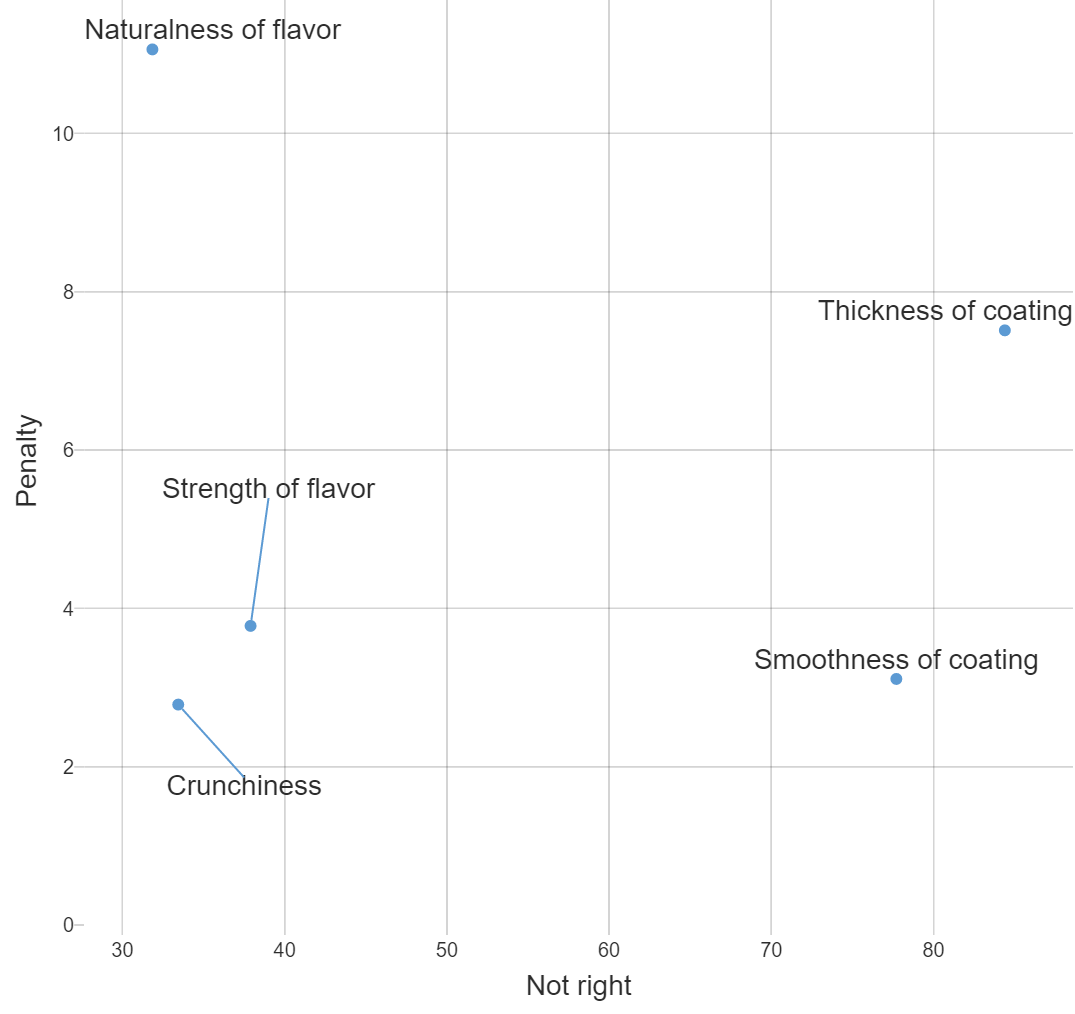
Product attributes which are top-most and right-most present the most concern as they both have a large drop-off on the liking scale and have the largest proportion of people who feel the product is “not right” in this area.
Want to find out how to do more in Displayr? Check out the Using Displayr section of our blog!
