

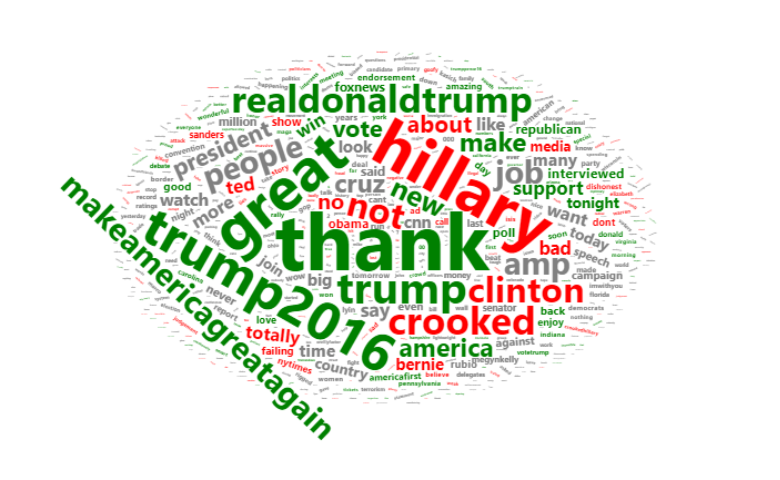
In this post, I describe how to create color-coded Word Cloud, where the colors are based on sentiment. Not only do you get to see which words are most prominent, but you get an idea of the tone with which they are used. The words in the Word Cloud are from tweets by President Trump. Green means that the words were mainly used in tweets with a positive sentiment. Red means the tweets were used in words with a negative sentiment. I start by describing the overall logic, and with more detailed instructions at the end of the post.
Extracting the words
The first step in performing a Word Cloud is to extract the words. You typically do not want to show all words. Otherwise you end up with “of”, “to”, “the” and “a” being the biggest words in the cloud. It is also a good idea to correct spelling mistakes, remove plurals, remove punctuation (e.g., capitalization), and automatically combine words that are almost identical (e.g., USA, US).
Fortunately, there are many ways of doing this automatically using various text analysis tools. I explain the details of how I have set this up below.
Ready to analyze your text?
Start a free trial of Displayr.
Sentiment for the phrases (tweets)
Although it is possible to perform sentiment analysis on the words themselves, the result is not very informative. In the case of clinton, for example, the word has neither positive nor negative meaning. To work out the sentiment of a particular word we need to work out the sentiment of the phrases in which it is used. We can do this using standard sentiment analysis algorithms.
The table below shows the sentiment for 1,512 of Trump’s tweets. Sentiment analysis is a crude tool. As an example, look at the second tweet. Why has this been given a positive sentiment score? It is because it contains the word available, and that can be seen as having a positive connotation. This is how sentiment analysis basically works. Words are classified as having positive or negative connotations or degrees of positiveness and negativeness. The overall sentiment of a phrase is computed by adding up the sentiment of the words. If you read through a few more of the tweets you should come to the conclusion that it is often imperfect, but on average gets the right conclusion. This means that it is a useful technique but we need to be a bit careful; I return to this below.
The sentiment scores in the table above tend to be larger for longer sentences. To take this effect out of the data I have recoded all negative scores as -1 and all positive scores as +1
Sentiment for each word
For each word, I have then computed the mean sentiment of all the phrases (tweets) that use that word. Where the word only appears in positive tweets it gets a score of 1. If it only appears in negative tweets, it gets a score of -1. It gets a score closer to 0 when the sentiment of phrases in which the word is used is less consistent.
In the table below, phrases where the word thank appears are almost always in positive tweets (as shown in the Sentiment column). The word hillary, on the other hand, is mainly shows up in negative tweets.
Computing the statistical significance of words
As mentioned above, the sentiment scores are only pretty rough approximations. We need to be careful about how we interpret them. Commonsense says that we need to take into account two things when interpreting the sentiment scores: the average sentiment and the number of tweets in which the word appears. For example, job, shown on the second page of words (click Next at the bottom of the table) has an average of 0.18 based on 106 tweets, which suggests it is perhaps it is a word associated with positive sentiment. By contrast, if you go to the last page of words (click on End), you will see wednesday has a sentiment score of 0.2 out of 5 tweets, which seems too little evidence to conclude that it is a positive word.
Fortunately, statistical inference was invented for this problem. I have used the most basic of all stat tests, the Z-Test, to compute Z-Scores for each of the words. The further the Z-Score from 0, the stronger the evidence. For example, job has a Z-Score of double that of wednesday.
Color-coding the Word Cloud
The last step is to create a rule about how to color the words. A common yardstick for interpreting Z-Scores is that a score of less than -1.96 or greater than 1.96 indicates “statistical significance” (aka 0.05 p-value aka 95% level of confidence). I have used this rule, coloring words red if less than -1.96, green with more than 1.96, and grey otherwise. Of course, there are many other things we could do, such as having the darkness of the color linked to the Z-Score or coloring based on other information, such as gender.
Make sure that long words are not missing
Sometimes words can be so long that they cannot be shown. Such words are automatically left of the Word Cloud, without a warning, so a bit of care is required to check that this does not happen. If you look at the table above, you can see it shows the length of the words. You should sort this out and make sure that any words that are long and have high frequencies (freq) are visible in the Word Cloud. If they are not, you need to increase the font size used in the Word Cloud until all the words are visible.
How to make your own color-coded Word Clouds
I list links to various software tools below. However, I will bring to your attention a couple of technical limitations:
- The Word Cloud changes each time it is computed.
- Sometimes you need to refresh your browser to have the Word Cloud compute.
- The wordcloud2() function used to create the Word Cloud will remove words if there isn’t enough space so care is needed to ensure the font is small enough to show all words in the output.
The simplest way to create a Word Cloud color-coded by sentiment is to use our Word Cloud With Sentiment Analysis Generator. We created this in Displayr.
If you want to create a sentiment-colored Word Cloud in R, please see How to Show Sentiment in Word Clouds using R.
To create a sentiment-colored Word Cloud in Q, please see How to Show Sentiment in Word Clouds using Q.
To create a sentiment-colored Word Cloud in Displayr, please see How to Show Sentiment in Word Clouds using Displayr.
Interested? You can try Displayr’s text analysis tool for free today.
Acknowledgements
I have performed the text analytics in my colleague Chris Facer’s flipTextAnalysis package (https://github.com/Displayr/flipTextAnalysis).
We created this Word Cloud using Dawei Lang’s wordcloud2 package (https://github.com/Lchiffon/wordcloud2).
The data used in this post is from http://varianceexplained.org/r/trump-tweets/.
