How to Interpret Correspondence Analysis Plots (It Probably Isn’t the Way You Think)

Correspondence analysis is a popular data science technique. It takes a large table, and turns it into a seemingly easy-to-read visualization. Unfortunately, it is not quite as easy to read as most people assume.
In How correspondence analysis works (a simple explanation), I provide a basic explanation of how to interpret correspondence analysis, so if you are completely new to the field, please read that post first. In this post, I provide lots of examples to illustrate some of the more complex issues.
How to interpret correspondence analysis
Correspondence analysis reduces the dimensionality of data. And while this means it is an effective way to simplify large tables, this does not always mean it is simple to interpret. There are a number of key concepts related to the interpretation of correspondence analysis, each with varying complexity.
Interpreting correspondence analysis effectively is crucial. It's how you find trends in the data and draw insights that inform business decisions. To make the most of this technique, it's important to go beyond the visual appeal of the map and understand what it’s really showing—and what it’s not. That starts with validating your insights against the original data.
1. Check conclusions using the raw data
The key to correctly interpreting correspondence analysis is to check any important conclusions by referring back to the original data. In this post I list 9 other things to think about when interpreting correspondence analysis. But, so long as you always remember this first rule, you will not go wrong.
The reason for this rule is illustrated in the example below. It shows 24 months of sales data by different retail categories. The visualization shows that Department stores are associated with December (i.e., Christmas, Dec-15 and Dec-16). We can see that Food retailing is on the opposite side of the map, which most people would interpret as meaning that Food retailing sales are lower in December.
Now, take a look at the actual data, shown below. Even though Food retailing is a long way from December on the map:
- Food retailing has the highest sales in December of any of the categories.
- Food retailing's biggest month is December.
How can this be? The data seems to say the exact opposite of visualization? If you have read How correspondence analysis works (a simple explanation), you should understand that this is because correspondence analysis is all about the relativities. If we dig deeper into the data we can see that the map above does make sense, once you know how to read it.
While Food retailing does peak at Christmas, its sales are only 19% above its average monthly sales. By contrast, Department store sales spike to 85% above average in December. This is what correspondence analysis is trying to show us. Correspondence analysis does not show us which rows have the highest numbers, nor which columns have the highest numbers. It instead shows us the relativities. If your interest is instead on which categories sell the most, or how sales change over time, you are better off plotting the raw data than using correspondence analysis.
2. The further things are from the origin, the more discriminating they are
The correspondence analysis plot below is from a big table consisting of 42 rows, each representing a different brand, and 15 columns. You can see the original data here. Correspondence analysis has greatly simplified the story in the data. As you hopefully remember from school, the origin is where the x- and y-axes are both at 0. It is shown below as the intersection of two dashed lines. The further labels are from the origin, the more discriminating they are. Thus, Lee Jeans (at the top) is highly differentiated. Similarly, Outdoorsy is a highly discriminating attribute.
3. The closer things are to origin, the less distinct they probably are
In the map above, we see that Qantas is bang smack in the middle of the visualization. Thus, the conclusion probably is that it is not differentiated based on any of the data in the study. I explain the use of the weasel-word "probably" in the next section.
Here is another example. In the center of the map we have Wallaby and Lucky. Does this mean wallabies are lucky animals? No. They get hit by cars a lot. If you follow rugby, you will know that 99 times out of 100 a Wallaby is no match for even a Kiwi. If you look at the table below, you can see that the Wallaby is pretty average on all the variables being measured. As it has nothing that differentiates it, the result is that it is in the middle of the map (i.e., near the origin). Similarly, Lucky does not differentiate, so it is also near the center. That they are both in the center tells us that they are both indistinct, and that is all that they have in common (in the data).
4. The more variance explained, the fewer insights will be missed
I have reproduced the correspondence analysis of the brand personality data below. You will hopefully recall my mentioning that Qantas being in the middle meant that it was probably not differentiated based on the data. Why did I write "probably"? If you sum up the proportion of variance explained by horizontal and vertical dimensions (shown in the axis labels), we see that visualization displays 57% of the variance in the data. And, remember, this is only 57% of the variance in the relativities. So, a lot of the data has been left out of the summary. Perhaps Qantas is highly differentiated on some dimension that is irrelevant for most of the brands; the only way to know for sure is to check the data.
Now, in fairness to correspondence analysis, it is important to appreciate that it is actually a great achievement for the map to explain 57% of the variation with such a large input table. To represent all of the relativities of this table requires 14 dimensions, but we have only plotted two. Correspondence analysis is not the problem. The problem is the quantity of the data. The more data, the greater the chance that any good summary will miss out important details.
5. Proximity between row labels probably indicates similarity (if properly normalized)
As discussed in some detail in How correspondence analysis works (a simple explanation), we should be able to gauge the similarity of row labels based on their distance on the map (i.e., their proximity). "Should" is another weasel word! Why? Three things are required in order for this to be true:
- We need to be explaining a high proportion of variance in the data. If we are not, there is always the risk that the two row labels are highly distinct, but are still shown on the map as if not distinct.
- The normalization, which is a technical option in correspondence analysis software, needs to have been set to either principal or row principal. I return to this in the next section.
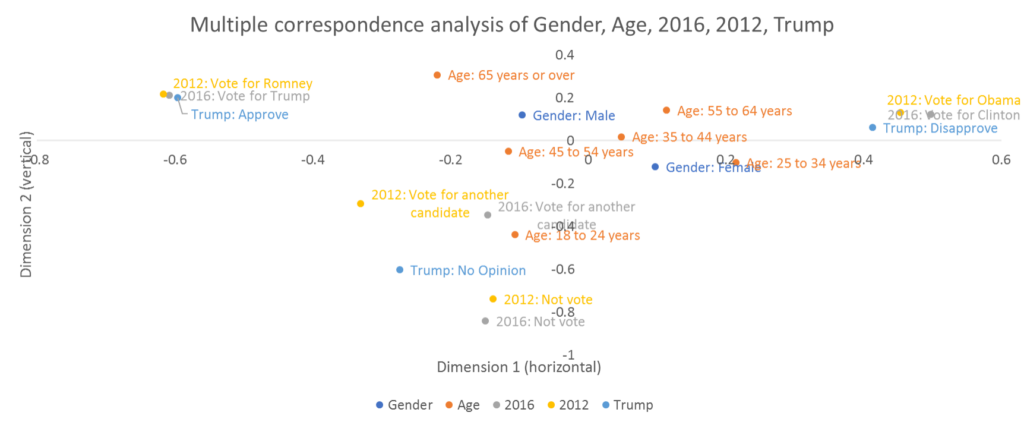
- The aspect ratio of the map needs to be fixed at 1. That is, the horizontal and vertical coordinates of the map need to match each other. If your maps are in Excel or, as in the example below, PowerPoint, you may well have a problem. In the chart below, the really big pattern is that there is an enormous gap between the pro-Trump camp, on the far left, and the pro-Clinton camp on the far right. If you have even a passing understanding of American politics, this will make sense. However, if you look at the scale of the labels on the x- and y- axes you will see a problem. A distance of 0.2 on the horizontal is equivalent to a distance of 0.6 on the vertical. The map below this has the aspect ratio set to 1, and it tells a different story. Yes, the pro- and anti-Trump camps are well apart, but the disenfranchised youth are now much more prominent.
6. Proximity between column labels indicates similarity (if properly normalized)
This is a repeat of the previous point, but applying to columns. Here, the normalization needs to be either principal or column principal. You may recall me writing in the previous point that to compare between rows, we need to be using either principal or row principal normalization. So, setting the normalization to principal seems the obvious solution. But, before jumping to this conclusion, which has its own problems (as discussed in the next section), I will illustrate what these different normalization settings look like. The visualization below is based on the principal normalization. Principal is the default in some apps, such as Displayr, Q, and the R package flipDimensionReduction. However, it is not the default in SPSS, which means that comparing the distances between rows labels in a map created by SPSS with defaults is dangerous.
The plot below uses the column principal normalization. If you look very carefully, you will see that the positions of the column points are unchanged (although the map has been zoomed out). But, the positions of the row labels, representing the brands, have changed. There are two ways that the row labels positions have changed. First, they have been stretched out to be further form the origin. Second, the degree of stretching has been greater vertically. With the principal plot shown above, the horizontal differences for the row labels are, in relative terms, bigger. With the column principal shown below, the vertical differences are bigger. So, to repeat the point made a bit earlier: the distances between the column points are valid for both principal and column principal, but the distances between the row points are not correct in the column principal shown below.
The visualization below shows the row principal normalization. Now the distances between the row labels are meaningful and consistent with those shown in the principal normalization, but the differences between the column coordinates are now misleading.
7. If there is a small angle connecting a row and column label to the origin, they are probably associated
Take a look at the plot above. Would you say Lift is more strongly associated with Cheers you up or Relax? If you have said Relax, you are interpreting the map correctly. As discussed in How correspondence analysis works (a simple explanation) it is wrong to look at the distance between row labels and column labels. Instead, we should imagine a line connecting the row and column labels with the origin. The sharper the angle, the stronger the relationship. Thus, there is a strong relationship between Relax and Lift (although, if you look at the data shown below, you will see that Lift is very small, so it does not in any sense "own" Relax).
If you have not yet had your coffee for the day, go get it now. We are at the hard bit. In the plot above, the angles are informative. However, interpreting the angles is only strictly valid when you have either row principal, column principal, or symmetrical (1/2) normalization. So, if wanting to make inferences about the relationships between the rows and columns (e.g., brands and attributes in the examples above), we are better off not using the default principal normalization. This is really the yuckiest aspect of correspondence analysis. No one normalization is appropriate for everything. Or, stated from a glass half full perspective, our choice of normalization is really a choice of how we want to mislead the viewer!
Additional complexity is added to this problem by the tendency of people not to report the normalization. Fortunately, we can make an educated guess based on the dispersion of the points (if the rows points are all near the origin we probably have row principal, and vice versa for columns).
Depending on the day of the week I have two ways of dealing with this issue. Most of the time, my preference is to use the principal normalization, and remind viewers to check everything in the raw data. Sometimes though, where my interest is principally in the rows of a table, I use row principal and a moon plot. Distances between the brands are plotted inside of a circle and these distances are meaningful. The column labels are shown on the outside of the circle. They have the same angles as on the plot above. But, now the font size represents what was previously indicated by the distance between the column labels and the origin. The beauty of this representation is that we can now compare distances between column labels and points, so the plot is much harder to misread, and we have no need to educate the reader about the whole reading of angles. The information regarding the relativities of the column labels is harder to gauge, but, this is arguably beneficial, as the construction of the plot makes it clear that the focuses is on the rows (brands).
8. A row and column label are probably not associated if their angle to the origin is 90 degrees
In the moonplot above, if you draw a line connecting Red Bull to the Origin, and back out to Kids, you will see that it is roughly a right-angle (90 degrees). This tells us that there is no association between Kids and Red Bull. Again, I have written "probably". If you look at the data, shown in the table above, there is clearly a negative association. Remember, always look at the data!
9. A row and column label are probably negatively associated if they are on opposite sides of the origin
The plot below shows the traits that people want in an American president by age. What do the 25 to 34 year old yearn for? The is a strong association with Entertaining. What is the next strongest association? You may think it would be concern about global warming and minorities. This is not the case. The next strongest associations are negative ones: the 25 to 34 year olds are less keen on a Christian President, one who has been successful in business, and one who is plain-speaking. We can see this because these traits are on the opposite side of the origin, and are a long way from the origin, whereas the traits relating to global warming and welfare of minorities are all closer to the origin, and thus are less discriminating.
Here's another example. The correct way to read this visualization is that Yahoo is, in relative terms, stronger than Google on Fun. However, if you look at the raw data it shows that Google is much more fun than Yahoo (54% versus 28%). The reason that Yahoo has stronger association with Fun is that it is its second best performing attribute (with 29% for Easy-to-use). By contrast, while Google is twice as fun as Yahoo, it scores three times as high on High quality, and High performance, which are on the opposite side of the map, and this is what drags Google away from Yahoo.
10. The further a point from the origin, the stronger their positive or negative association
The visualization below shows movement of Yahoo's perceptions from 2012 to 2017, with the arrow head showing 2017 and the base of the arrow showing 2012. The obvious way to read this is that Yahoo has become more fun, more innovative, and easier-to-use. However, such a conclusion would be misplaced.
A better interpretation is:
- In 2012, the angle formed by connecting the base of Yahoo to the origin and back to Fun is very small, which tells us that they are associated.
- As Fun is relatively far from the origin we know that Fun is a relatively good discriminator between the brands.
- As Yahoo was very far from the origin, and associated with Fun, we can conclude that Yahoo and Fun were closely associated in 2012 (remember, correspondence analysis focuses on relativities; in 2012 Yahoo's Fun score was half of Google's).
- From 2012 to 2017, Yahoo moved much closer to the origin, which tells us that Yahoo's relative strengths in terms of Fun, Easy-to-Use, and Innovative, have likely declined (and, in reality, they have declined sharply; Google is now more than four times as fun).
Correspondence analysis interpretation
It is really, really, important to always check key conclusions from correspondence analysis by inspecting the raw data. This helps ensure that what you’re seeing in the visualization genuinely reflects the underlying patterns, rather than artifacts of the analysis.
R for correspondence analysis
Hopefully you like the look of the plots in this post! They can all be created in R using the Displayr/flipDimensionReduction package, or in Displayr and Q via the menus. More detail about the various plots shown in this post, and R code, can be found in the other correspondence analysis posts on this blog.
Easily create your own correspondence analysis in Displayr. Get started free.