


Data stacking is a data preparation step where a data set is split into subsets, and the subsets are merged by case (or stacked on top of one another). The number of variables in the data decreases, and the number of cases increases. In this article we look at how to stack data that has been loaded into SPSS Statistics, using both the interactive wizard and using syntax via the VARTOCASES command. We used SPSS version 23.
A worked example
In this example we consider data from a simple survey which asked people about how they rate different technology brands. You can download the data file that we used from:
https://wiki.q-researchsoftware.com/images/3/35/Technology_2018.sav
A subset of the data before and after stacking is shown in the image below.
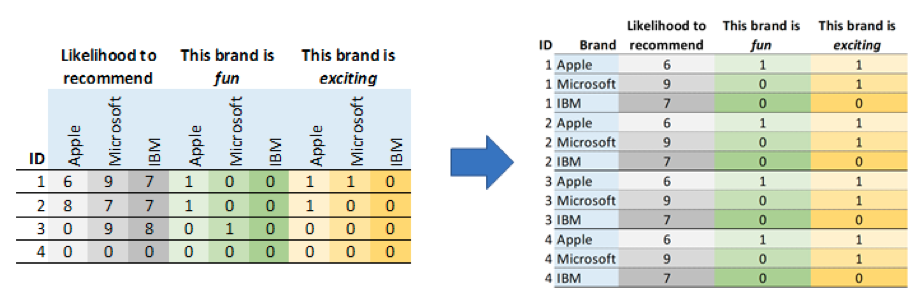
Before you start stacking you should work out:
- Which variables are to be stacked, and how many stacked variables will there be in the final data set? In the image above, there are 3 stacked variables in the final stacked data. In our complete example there are 10.
- Which variable is the ID variable?
- Which other variables in the data are to be included but not stacked? These will be stretched, which means that their values will be repeated several times for each of the original cases.
The SPSS Restructure Data Wizard
Once you have your data set loaded into SPSS you can stack your data file using the following steps. There are some additional options along the way which you can select according to your needs. These steps focus on stacking the example data file linked above.
- Select Data > Restructure. This will open the Restructure Data Wizard.
- Choose the option to Restructure selected variables into cases, and click Next.
- Choose to stack More than one variable, and enter the number of groups of variables that you are stacking. In this example there are 10 groups of variables (one for the Likelihood to recommend survey question, and 9 groups of brand attribute variables). Click Next.
- Choose one of the variables in the data file to be the ID variable, and select it in the Case Group Identification
- Describe each group of stacked variables in the Variables to be Transposed section:
a. Choose the Target Variable. SPSS has created generic names for these, which will be trans1, trans2, etc.
b. Highlight the variables for the group in the list on the left, and use the arrow button to move them into box below Target Variable.
Move any variables which you want to keep in the data, but which do not need to be stacked, into box under Fixed Variable(s). These variables will be stretched.
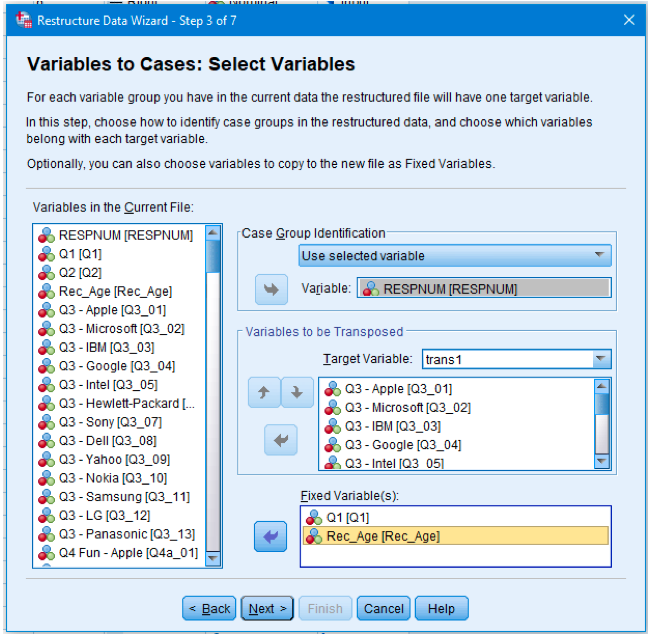
7. Click Next.
8. Select the option for creating a Single index variable and click Next. The index variable keeps track of which original variable each case in the stacked data corresponds to.
9. Select Sequential numbers for your index variable and click Finish.
The new stacked data will become available in the Variable View.
Syntax
The example above produces the following syntax which can be saved for later use or modification:
GET
FILE=’C:\Users\Chris\Downloads\Technology_2018.sav’.
DATASET NAME DataSet1 WINDOW=FRONT.
VARSTOCASES
/MAKE trans1 FROM Q3_01 Q3_02 Q3_03 Q3_04 Q3_05 Q3_06 Q3_07 Q3_08 Q3_09 Q3_10 Q3_11 Q3_12 Q3_13
/MAKE trans2 FROM Q4a_01 Q4a_02 Q4a_03 Q4a_04 Q4a_05 Q4a_06 Q4a_07 Q4a_08 Q4a_09 Q4a_10 Q4a_11 Q4a_12 Q4a_13
/MAKE trans3 FROM Q4b_01 Q4b_02 Q4b_03 Q4b_04 Q4b_05 Q4b_06 Q4b_07 Q4b_08 Q4b_09 Q4b_10 Q4b_11 Q4b_12 Q4b_13
/MAKE trans4 FROM Q4c_01 Q4c_02 Q4c_03 Q4c_04 Q4c_05 Q4c_06 Q4c_07 Q4c_08 Q4c_09 Q4c_10 Q4c_11 Q4c_12 Q4c_13
/MAKE trans5 FROM Q4d_01 Q4d_02 Q4d_03 Q4d_04 Q4d_05 Q4d_06 Q4d_07 Q4d_08 Q4d_09 Q4d_10 Q4d_11 Q4d_12 Q4d_13
/MAKE trans6 FROM Q4e_01 Q4e_02 Q4e_03 Q4e_04 Q4e_05 Q4e_06 Q4e_07 Q4e_08 Q4e_09 Q4e_10 Q4e_11 Q4e_12 Q4e_13
/MAKE trans7 FROM Q4f_01 Q4f_02 Q4f_03 Q4f_04 Q4f_05 Q4f_06 Q4f_07 Q4f_08 Q4f_09 Q4f_10 Q4f_11 Q4f_12 Q4f_13
/MAKE trans8 FROM Q4g_01 Q4g_02 Q4g_03 Q4g_04 Q4g_05 Q4g_06 Q4g_07 Q4g_08 Q4g_09 Q4g_10 Q4g_11 Q4g_12 Q4g_13
/MAKE trans9 FROM Q4h_01 Q4h_02 Q4h_03 Q4h_04 Q4h_05 Q4h_06 Q4h_07 Q4h_08 Q4h_09 Q4h_10 Q4h_11 Q4h_12 Q4h_13
/MAKE trans10 FROM Q4i_01 Q4i_02 Q4i_03 Q4i_04 Q4i_05 Q4i_06 Q4i_07 Q4i_08 Q4i_09 Q4i_10 Q4i_11 Q4i_12 Q4i_13
/INDEX=Index1(13)
/KEEP=RESPNUM Q1 Rec_Age
/NULL=KEEP.
Tidying and saving the data
To finish off your new stacked data file you can do some basic tidying in the Variable View:
- Click into the entries in the Label column and remove reference to specific brands or other properties of the original variables. In this example, the Label of my first new variable is Q3 – Apple, but the reference to the brand name Apple is erroneous since we have stacked over the brands.
- Change the Name of Index1 to Brand (or whatever is appropriate for your data set.
- Click into the button in the Values column for your index variable, and add labels for each of the index values. For each value (1 to 13 in this example):
a. Type the value into the Value
b. Type the corresponding brand name into the Label box.
c. Click Add.
More info on general data stacking can be found in The Data Story Guide.
