
How to Create a Correlation Matrix in R
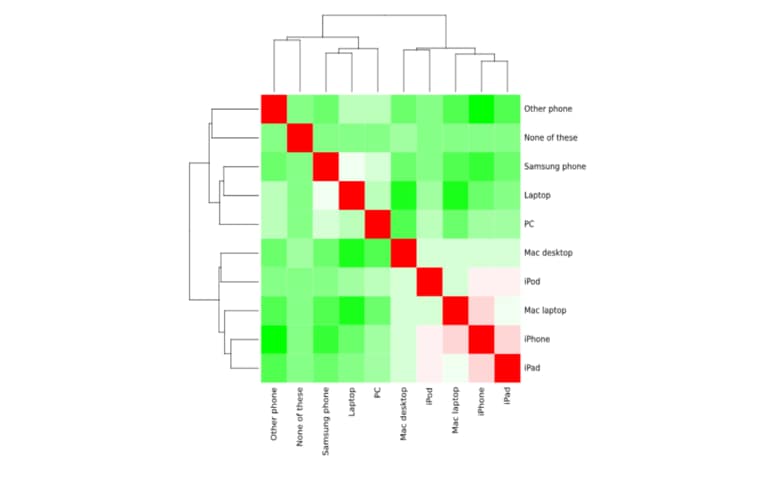
A correlation matrix is a table of correlation coefficients for a set of variables used to determine if a relationship exists between the variables. The coefficient indicates both the strength of the relationship as well as the direction (positive vs. negative correlations). In this post, I’ll show you how to calculate and visualize a correlation […]
Text Analysis: Hooking up Your Term Document Matrix to Custom R Code

I have previously written about some of the text analysis options that are available in Displayr: sentiment analysis, text cleaning, and the predictive tree. As text analysis is a growing field, you likely want to use your own tools on top of those already built into Displayr. To feed information about your text into a statistical […]
Building Online Interactive Simulators for Predictive Models in R

Correctly interpreting predictive models can be tricky. One solution to this problem is to create interactive simulators, where users can manipulate the predictor variables and see how the predictions change. This post describes a simple approach for creating online interactive simulators. It works for any model where there is a predict method. Better yet, if the […]
Linear Discriminant Analysis in R: An Introduction

Linear Discriminant Analysis (LDA) is a well-established machine learning technique and classification method for predicting categories. Its main advantages, compared to other classification algorithms such as neural networks and random forests, are that the model is interpretable and that prediction is easy. Linear Discriminant Analysis is frequently used as a dimensionality reduction technique for pattern […]
Automatically Fitting the Support Vector Machine Cost Parameter

In an earlier post I discussed how to avoid overfitting when using Support Vector Machines. This was achieved using cross validation. In cross validation, prediction accuracy is maximized by varying the cost parameter. Importantly, prediction accuracy is calculated on a different subset of the data from that used for training. In this blog post I take that […]