


Survey data processing is the crucial step that follows the collection of any survey data. The aim of data processing is to manipulate or transform raw data into meaningful results which can be analyzed in any statistical software tool, and ultimately presented in a way that answers the intended research question.
Steps in Survey Data Processing
While the specific steps vary by project, survey data processing typically follows this sequence:
- Data collection and import — Raw responses are exported from the survey platform and imported into analysis software.
- Quality assurance — Responses are checked for speedsters, flatliners, and nonsensical answers, and removed if necessary.
- Data cleaning — Outliers are identified, missing values are handled, and any data entry errors are corrected.
- Coding — Open-ended responses are categorised into themes so they can be analysed quantitatively.
- Variable construction — New variables are created where needed, such as net scores, indices, or recoded categories.
- Weighting — If the sample does not reflect the target population, weights are applied to correct for imbalances.
- Export for analysis — The cleaned, weighted dataset is prepared for crosstabulation, statistical modelling, or visualisation.
Modern tools can automate several of these steps. Displayr’s Data Preparation Agent handles quality checks, variable construction, and open-ended coding automatically — reducing manual processing time significantly.
Quality assurance
A central component of processing customer feedback survey data is quality assurance – ensuring that the data is of high quality and therefore presents valid results. Data processing involves several stages, including logic checking and data cleaning.
The data processor will check the logic to ensure that the data which has been collected, has been collected correctly and that there is no missing or erroneous data. That is, checking that no individual has answered a question they were not supposed to answer and no one has missed a question that they should have answered.
Data cleaning, on the other hand, deals with identifying outliers and removing respondents who have given contradictory, invalid or dodgy responses, or are potential duplicate records. Common forms of cleaning include identifying speedsters, flatliners, and nonsensical or obscene open-text responses.
- Speedster: A respondent who completes the survey in a fraction of the time they should have. Therefore, it is believed that they could not have possibly read and answered all the questions properly in the time taken. As each survey has a set expected length, you can measure this against the individual duration of the entire survey, or specific sections (if recorded), to identify speedsters.
- Flatliner: A respondent that gives the same response for each item in a series of ratings (such as “On a scale of 1 to 5 where 1 means ‘Not very satisfied’ and 5 means ‘Very satisfied’, how would you rate each of the following supermarkets?”).
- Nonsensical: Someone may also write random letters or numbers instead of giving a legitimate answer to an open-text response question. Similar repeated behavior on key questions will often be used as a justification for removing an individual’s record from the data set.
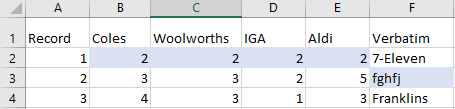
Highlighted below is an example of a flatliner and respondent who has given a nonsensical answer:
Data preparation and production
The final step in the data processing stage is to ensure that the data can be used for analysis. This may require adjustments and transformations, including data entry, editing, rebasing, filtering, and reconstructing. If verbatim responses (open-ended questions) have been collected, they may need to be coded down to a more manageable number of themes and comments.
Modern survey processing tools can now automate much of this work. Displayr’s Data Preparation Agent automatically checks, cleans, and structures survey data—renaming variables, fixing reversed scales, flagging low-quality or inconsistent responses, and creating derived variables like NPS and Top-2-Box scores. It even categorizes open-ended text responses using AI, saving researchers hours of manual preparation while ensuring every dataset is consistent and analysis-ready. Learn more about the Data Preparation Agent.
Data weighting may also be required to correct issues with sampling inconsistencies or to ensure the data is representative of the target population. Once the data is prepared, it can then be presented through statistics in tables, charts, or dashboards.
