


We’ve significantly enhanaced our automatic text categorization algorithms and streamlined the workflow, to cut down the time to get from raw to fully coded data
Overview
Displayr’s text coding functionality is designed with needs of the survey researcher front and centre. For many years the text categorization functions in Displayr have already supported what we might call a manual workflow. We make it easy to view, sort, and filter text responses, create and structure categories, and assign or code responses to those categories. More recently we’ve added semi-automated functions to the interface and extensively upgraded the algorithms that drive them. We believe our tools in this space are state-of-the-art …
- In selecting “Semi-Automatic” Text Categorization, users are presented immediately with a draft set of categories with the bulk of the data already coded. So in a matter of minutes you are off to a great start
- The algorithms that create this output are based on analysing context and meaning (not word similarity, like many other tools). Your draft code frames are intuitive from the get-go
- We’ve made this work effectively for multiple response categorizations, (where responses can be assigned to more than one code), which are historically more challenging to automate
- For tracking and related research, we have specific algorithms that recognize and categorize unaided brand awareness questions
- Once you have your draft categories, the user interface makes it easy to edit, with tools to combine, rename, and split categories
So the workflow now becomes:
- Let Displayr do the hard work and get you most of the way there (via a draft categorization), but in a fraction of the time it would take manually
- You then fine tune and edit the categories via the intuitive user-interface.
Accessing the automated functions
The quickest way to do this is to select a text variable in the Data Set tree, hover above or below it to ‘+’ insert a new variable, and follow the prompts via the Semi-Automatic menu path:
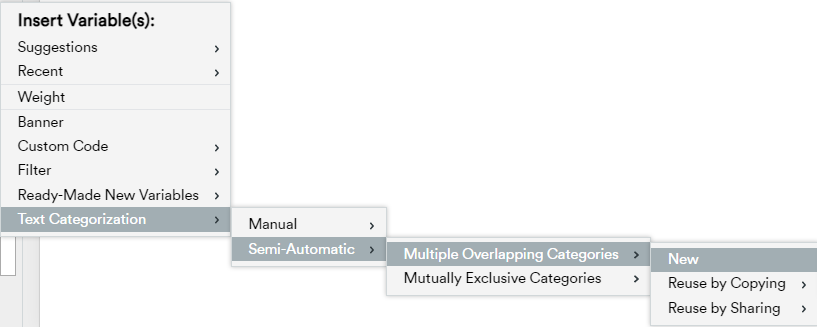
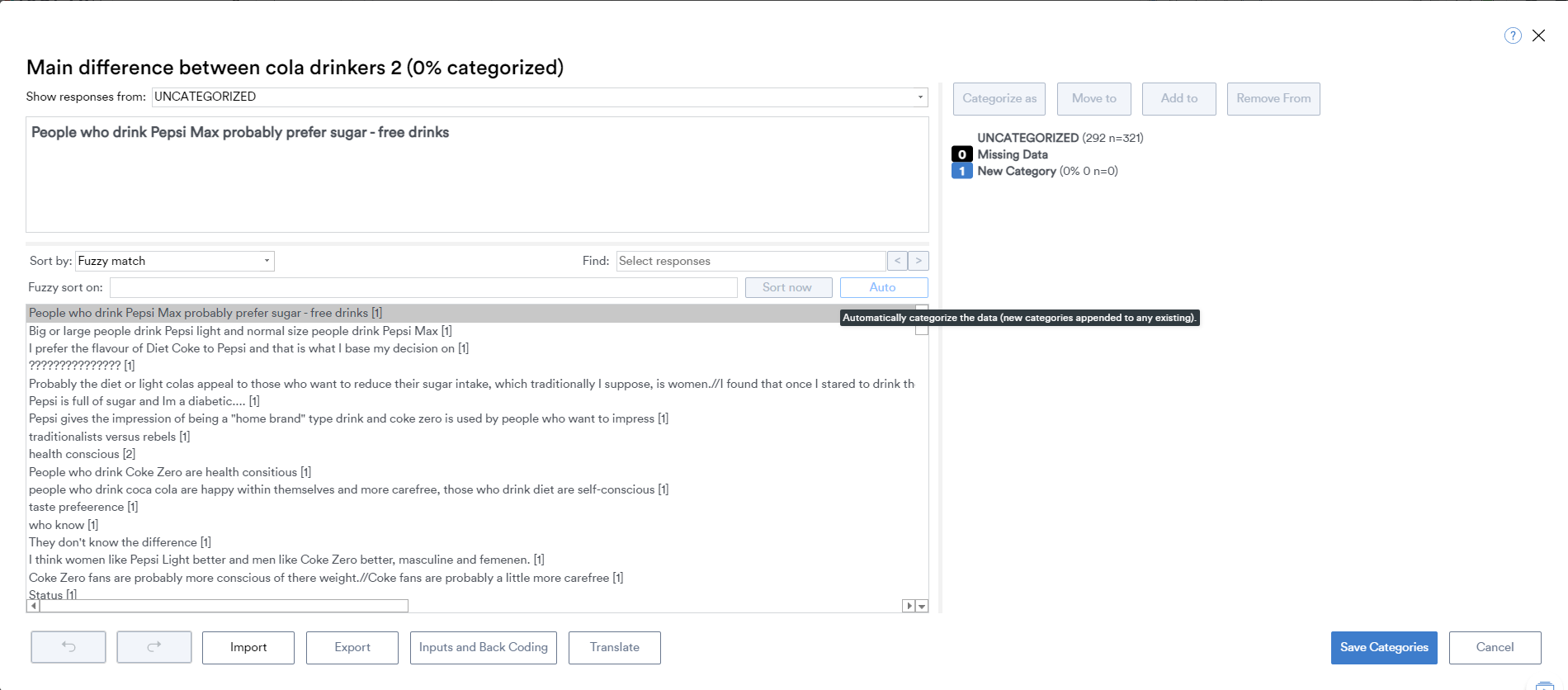
We know some users might want to start the process manually. This could involve reading through some responses and create some pre-planned categories. Even if you follow the Manual menu path, you can access the Automatic categorization function. At any time you can speed up the coding of remaing uncategorized data. In the categoriztion interface, set “Sort by:” to Fuzzy match, (as matching is a key building block of the algorithm), and the “Auto” button appears:
The functionality and workflow in action
Take a look at the process in action in this short video. It uses an open ended question on how people feel about ‘Tom Cruise’ as input*
You can get a broader overview of text analysis methods and solutions in this webinar recording. How to quickly analyze text data
Streamline your text data analysis.
The process of turning open text responses into usable data is traditionally time consuming and expensive (being often outsourced). Displayr’s text categorization tools are state of the art. You can create a draft categoriztion in minutes automatically and then quickly fine tune it into a polished codeframe. If you use a lot of text data and want to know more, book a demo or take a free trial.
* Discretion is advised – the data used in the video is from a real survey containing unvarnished attitudes to Tom Cruise. Some respondents have written unkind, distasteful and potentially offensive things. Displayr does not condone or endorse any of the comments that have been made.[/vc_column_text][/vc_column][/vc_row]
