



If you are not familiar with random forests, see my earlier article “What is a Random Forest?” before proceeding with this one. The process of fitting a single decision tree is described in “How is Splitting Decided for Decision Trees?” Random forest trees follow similar steps, with the following differences.
Data sampling
The training data for each tree is created by sampling from the full data set with replacement. This process is illustrated below.
The column on the left contains all the training data. The random samples have the same total number of cases as all the training data. Because cases are chosen randomly, some cases are repeated within a sample, and some cases are not present. Each sample consists of different cases.
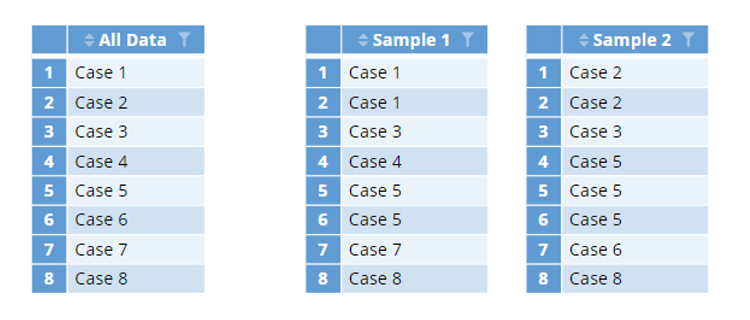
The cases that are not chosen for a given sample are called out-of-bag. Although they will not used for that specific tree, they may perform a role in accuracy measurement of the forest. They may also be present in the sample for another tree.
Variable sampling
When deciding which variable to split in a forest, only certain variables are considered. If there are p predictor variables, then usually sqrt(p) are randomly chosen for consideration for each split in a classification task. In a regression task, p/3 variables are randomly chosen.
Given the data and variable sampling, each tree is trained in a process very similar to the way a single decision tree is trained. The data is passed down the tree and at each node the best splitting variable is chosen. The data is partitioned according to the split to form two new nodes. This process repeats until we reach a leaf.
No early stopping
An important difference between training a single tree and a tree within a forest is that for classification tasks, forest trees are usually trained until the leaf nodes contain one sample, or only samples from a single class. By contrast, training of a stand-alone tree usually stops before such leaf purity to avoid overfitting. Stand-alone trees may also use cross-validation and pruning to stop training. Neither are used within a forest. For regression tasks (i.e., predicting a numeric outcome) forest trees usually stop training with leaves containing five or fewer samples.
Prediction
When classifying outputs, the prediction of the forest is the most common prediction of the individual trees. For regression, the forest prediction is the average of the individual trees.
Because forests average many different trees, each of which are built and trained differently, the predictions of the forest exhibit less overfitting than a single tree. The random choices of splitting variable reduce the variance below that achievable through bagging alone, at the cost of a slight increase in bias.
Make your own random forest in Displayr, or check out our other blogs about data science!
