


If you want to do your own hierarchical clustering, use the template below – just add your data!
The strengths of hierarchical clustering are that it is easy to understand and easy to do. The weaknesses are that it rarely provides the best solution, it involves lots of arbitrary decisions, it does not work with missing data, it works poorly with mixed data types, it does not work well on very large data sets, and its main output, the dendrogram, is commonly misinterpreted. There are better alternatives, such as latent class analysis.
Easy to understand and easy to do…
There are four types of clustering algorithms in widespread use: hierarchical clustering, k-means cluster analysis, latent class analysis, and self-organizing maps. The math of hierarchical clustering is the easiest to understand. It is also relatively straightforward to program. Its main output, the dendrogram, is also the most appealing of the outputs of these algorithms.
… But rarely provides the best solution
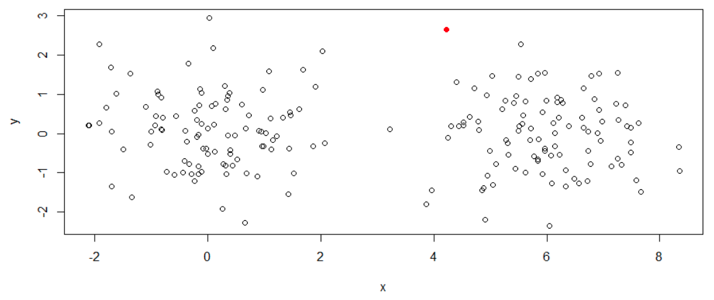
The scatterplot below shows data simulated to be in two clusters. The simplest hierarchical cluster analysis algorithm, single-linkage, has been used to extract two clusters. One observation — shown in a red filled circle — has been allocated into one cluster, with the remaining 199 observations allocated to other clusters.
It is obvious when you look at this plot that the solution is poor. It is relatively straightforward to modify the assumptions of hierarchical cluster analysis to get a better solution (e.g., changing single-linkage to complete-linkage). However, in real-world applications the data is typically in high dimensions and cannot be visualized on a plot like this, which means that poor solutions may be found without it being obvious that they are poor.
Arbitrary decisions
When using hierarchical clustering it is necessary to specify both the distance metric and the linkage criteria. There is rarely any strong theoretical basis for such decisions. A core principle of science is that findings are not the result of arbitrary decisions, which makes the technique of dubious relevance in modern research.
Missing data
Most hierarchical clustering software does not work with values are missing in the data.
Data types
With many types of data, it is difficult to determine how to compute a distance matrix. There is no straightforward formula that can compute a distance where the variables are both numeric and qualitative. For example, how can one compute the distance between a 45-year-old man, a 10-year-old girl, and a 46-year-old woman? Formulas have been developed, but they involve arbitrary decisions.
Misinterpretation of the dendrogram
Dendrograms are provided as an output to hierarchical clustering. Many users believe that such dendrograms can be used to select the number of clusters. However, this is true only when the ultrametric tree inequality holds, which is rarely, if ever, the case in practice.
There are better alternatives
More modern techniques, such as latent class analysis, address all the issues with hierarchical cluster analysis.
