


To create your own decision tree, use the template below.

The decision tree is typically read from top (root) to bottom (leaves). A question is asked at each node (split point) and the response to that question determines which branch is followed next. The prediction is given by the label of a leaf.
The diagram below shows a decision tree which predicts how to make the journey to work.
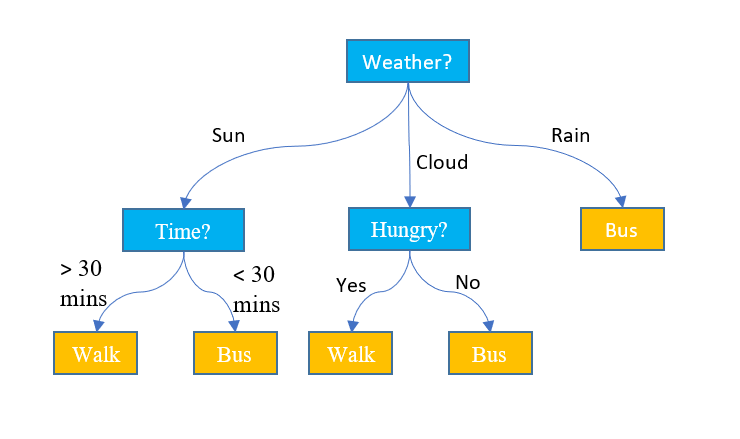
The first question asked is about the weather. If it’s cloudy, then the second question asks whether I am hungry. If I am, then I walk, so I can go past the café. However, if it’s sunny then my mode of transport depends on how much time I have.
The responses to questions and the prediction may be either:
- Binary, meaning the response is yes/no or true/false as per the hungry question above
- Categorical, meaning the response is one of a defined number of possibilities, e.g. the weather question
- Numeric, an example being the time question
How a decision tree is created
The small example above represents a series of rules such as “If it’s raining, I take the bus.” If the rules are known in advance, the tree could be built manually.
In real-world examples, we often don’t have rules, but instead have examples. The examples are in the form of a data set of instances or observations. Each instance consists of several predictor variables and a single outcome. The predictor variables are the questions and the outcome is the prediction. An example of such data is shown in the table below.
| Outcome | Weather | Hungry | Time |
|---|---|---|---|
| Bus | Rain | No | >30 mins |
| Walk | Cloud | Yes | <30 mins |
| Walk | Sun | No | >30 mins |
| Bus | Cloud | No | >30 mins |
| Bus | Sun | Yes | <30 mins |
Given this data, the general framework for building a decision tree is as follows:
- Set the first node to be the root, which considers the whole data set.
- Select the best variable to split at this node.
- Create a child node for each split value of the selected variable.
- For each child, consider only the data with the split value of the selected variable.
- If the examples are perfectly classified then stop. The node is a leaf.
- Otherwise repeat from step 2 for each child node until a leaf is reached.
This outline is followed by popular tree-building algorithms as CART, C4.5 and ID3.
This is a greedy algorithm, meaning that for each node, it uses local information to find best split for that node. An implication is that it may be possible to create a better tree by changing the order of the splitting variables.
Trees have a high degree of flexibility in the relationships that they can learn, which is known as having low bias. The downside of this is that they can learn the noise in the data, known as high variance. High variance often leads to overfitting, whereby the tree makes over-confident predictions.
Advantages of decision trees
There are several reasons to consider decision trees, including:
- The tree output is easy to read and interpret
- They are able to handle non-linear numeric and categorical predictors and outcomes
- Decision trees can be used as a baseline benchmark for other predictive techniques
- They can be used as a building block for sophisticated machine learning algorithms such as random forests and gradient-boosted trees
Disadvantages of decision trees
- Trees are subject to overfitting, due to the data being repeatedly split into smaller subsets. However, overfitting may be mitigated by pruning and early-stopping.
- The greedy algorithm causes a bias towards the best splitting variables being closest to the root.
- For complex problems, the performance may be inferior to that of more sophisticated predictive techniques.
For more information on decision trees, see “How is Splitting Decided for Decision Trees?” and “Pruning Decision Trees“.
You can create your own decision trees in Displayr by clicking on the template below.