


Raw data typically refers to tables of data where each row contains an observation and each column represents a variable that describes some property of each observation. Data in this format is sometimes referred to as tidy data, flat data, primary data, atomic data, and unit record data. Sometimes raw data refers to data that has not yet been processed.
Example
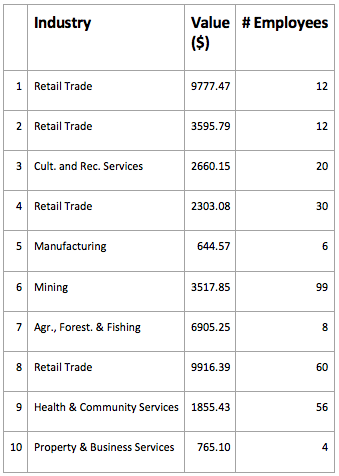
In the table below, each row (observation) represents a business customer of a telecommunications company, and the columns (variables) represent each company’s: industry, the value that the company represents to the owner of the data, and number of employees. Typically, raw data tables are much larger than this, with more observations and more variables.
The importance of raw data
Most data analysis and machine learning techniques require data to be in this raw data format.
Obtaining raw data
Although it is typically required for data analysis, it is not a space-efficient format, nor is it an efficient format for data entry, so it is rare that data is stored in this format for purposes other than data analysis. Consequently, it is typically obtained by extracting a data file which is explicitly created to be in this format. The most common format is a CSV data file, but there are many other file formats.
Other names for observations and variables
Other names for an observation in raw data include: row, case, response, unit of analysis, unit, record, and measurement. A variable can be referred to as a column, field, property, characteristic, quality, and, confusingly, measurement.
Data that has not yet been processed
Typically, the data that is most readily available for use is not in a state in which it can be used easily. For example, data recording what people may have purchased when buying their groceries may initially be in the form of a long list, consisting of the name of each person and the date, followed by what they purchased. Such data is difficult to manipulate and typically needs to be processed in some way before it can be used in standard data analysis software. Data which has yet to be processed is sometimes referred to as raw data, although source data is a more useful term.