


String splitting is the process of breaking up a text string in a systematic way so that the individual parts of the text can be processed. For example, a timestamp could be broken up into hours, minutes, and seconds so that those values can be used in the numeric analysis. One piece of information becomes three separate pieces of information:

Here the string is split based on “:”, but other approaches are possible, such as specifying the beginning and end positions of the text you want to extract.
What is a Text String?
A text string is any sequence of characters consisting of either numbers, letters, or symbols. In some cases these strings can hold meaning as in dates (05/04/15), times (06:45:59), or geographic location (Miami-FL). In each of these cases, different segments of the text strings hold a specific meaning. For example, in the timestamp, the colons “:” separate the hours, minutes and seconds.
Common Applications
Splitting text strings is an imperative step in data analysis to be able to better extract meaning from captured data. In practice, splitting is most often about choosing a character or substring and separating the text based on that. Commonly used characters that specify breaks in text strings are commas, colons, or spaces. The following applications demonstrate situations where text splitting is routinely applied.
Comma-Separated Values
Multiple response data is common in survey research, but it can sometimes be captured with one string of data with each answer separated by a comma as opposed to single variables for each response. For example, if there are 6 choices to choose from and a respondent chooses the first, second, and sixth choices, their answer may be recorded as “1,2,6”. This text would need to be separated out to conduct any analysis. In this case, separating the text by the comma would yield the data required.
Text Analysis
While many software programs now include tools for data analysis, splitting text responses can be used as a basic means for analyzing. This process is commonly referred to as tokenization, named for the resulting text segments which are called tokens. This can be useful when analyzing open-ended survey responses, tweets, or online reviews. In the example of the text string “I hated my food. I left early.”, splitting the text by spaces and punctuation into the individual words allows for the tokens to be counted or transformed.

Timestamps
It is difficult to perform any type of mathematical or statistical function on timestamps unless they are converted into a single unknit of measure. This process requires first breaking up the timestamp into its parts.
For example, splitting a timestamp “15:42:53” by the character “:” would yield the hours, minutes, and seconds for the timestamp, respectively.
Record ID Numbers
Most databases include a unique identifier field that includes a unique text string for each record of data. While this field can commonly be populated with simple sequential numbers, it can also be built from codes that assign descriptions to the record. In these situations, the ability to split the text string into its parts adds multiple layers of added value to the data to be analyzed.
For example, a record ID defined as “Molly-Johansen-13:24:06” might contain a respondent’s first name, last name, and a timestamp of when they completed a survey. Splitting this text string into its parts by the character “-” affords you three separate data points for analysis.
Vehicle VIN Numbers
In the case of a vehicle VIN Number, each of its 17 digits hold a unique meaning. By breaking the text up into its parts, you can see codes that signify information like the vehicle’s make, model, body style, and more.
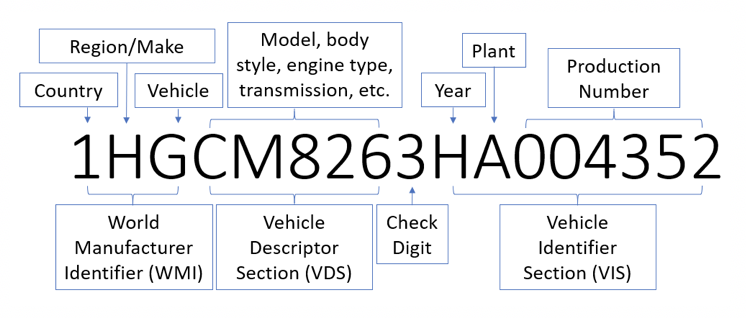
Online resources can provide the definitions for the codes present in VIN numbers (https://www.carfax.com/blog/vin-decoding).
For example, in the VIN number “1HGCM8263HA004352”, the first character denotes the vehicle’s country of origin and the tenth digit denoted the vehicle’s year. Splitting this text into its parts would tell us that the vehicle originates in the United States and has a 2017 model year. In this case, it is not possible to split based on a character. Instead, splitting would need to extract characters from specific positions.
String splitting by software
| String splitting in Excel | Data > Text to Columns > Set parameters for splitting text by a delimiting character or fixed width |
| String splitting with JavaScript | string.split(separator, limit) |
| String splitting in R | strsplit(x, separator) |
| String splitting in Q | Create > Variables and Questions > Variable(s) > JavaScript Formula > Text/Numeric and then use string.split(separator, limit) |
| String splitting in Displayr | Data Manipulation > JavaScript > Text Variable/Numeric Variable and then use string.split(separator, limit) |