

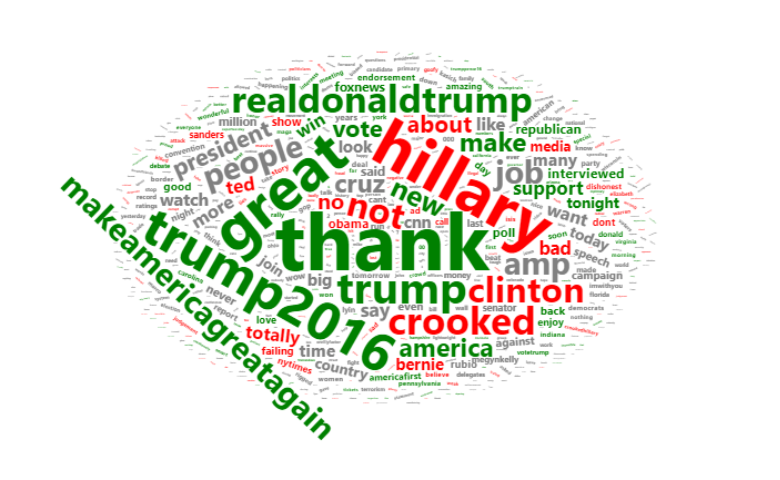
The Word Cloud above summarizes some data from tweets by President Trump. The green words are words that are significantly more likely to be used in tweets with a positive sentiment. The red represents words more likely to be used in negative tweets.
The code I used to create this tweet is below. All you need to do to run is to make sure you have installed the relevant packages (from github), and replace input.phrases in the first line with your data. Please read How to Show Sentiment in Word Clouds blog for a more general discussion of the logic behind the code below, and the How to Show Sentiment in Word Clouds article in our Displayr Help Center for how to create this in Displayr.
The R code
library(flipTextAnalysis)
text.to.analyze <- input.phrases
# Converting the text to a vector
text.to.analyze <- as.character(text.to.analyze)
# Extracting the words from the text
library(flipTextAnalysis)
options = GetTextAnalysisOptions(phrases = '',
extra.stopwords.text = 'amp',
replacements.text = '',
do.stem = TRUE,
do.spell = TRUE)
text.analysis.setup = InitializeWordBag(text.to.analyze, min.frequency = 5.0, operations = options$operations, manual.replacements = options$replacement.matrix, stoplist = options$stopwords, alphabetical.sort = FALSE, phrases = options$phrases, print.type = switch("Word Frequencies", "Word Frequencies" = "frequencies", "Transformed Text" = "transformations"))
# Sentiment analysis of the phrases
phrase.sentiment = SaveNetSentimentScores(text.to.analyze, check.simple.suffixes = TRUE, blanks.as.missing = TRUE)
phrase.sentiment[phrase.sentiment >= 1] = 1
phrase.sentiment[phrase.sentiment <= -1] = -1
# Sentiment analysis of the words
final.tokens <- text.analysis.setup$final.tokens
td <- t(vapply(text.analysis.setup$transformed.tokenized, function(x) {
as.integer(final.tokens %in% x)
}, integer(length(final.tokens))))
counts <- text.analysis.setup$final.counts
phrase.word.sentiment <- sweep(td, 1, phrase.sentiment, "*")
phrase.word.sentiment[td == 0] <- NA # Setting missing values to Missing
word.mean <- apply(phrase.word.sentiment,2, FUN = mean, na.rm = TRUE)
word.sd <- apply(phrase.word.sentiment,2, FUN = sd, na.rm = TRUE)
word.n <- apply(!is.na(phrase.word.sentiment),2, FUN = sum, na.rm = TRUE)
word.se <- word.sd / sqrt(word.n)
word.z <- word.mean / word.se
word.z[word.n <= 3 || is.na(word.se)] <- 0
words <- text.analysis.setup$final.tokens
x <- data.frame(word = words,
freq = counts,
"Sentiment" = word.mean,
"Z-Score" = word.z,
Length = nchar(words))
word.data <- x[order(counts, decreasing = TRUE), ]
# Working out the colors
n = nrow(word.data)
colors = rep("grey", n)
colors[word.data$Z.Score < -1.96] = "Red"
colors[word.data$Z.Score > 1.96] = "Green"
# Creating the word cloud
library(wordcloud2)
wordcloud2(data = word.data[, -3], color = colors, size = 0.4)
