
What is.
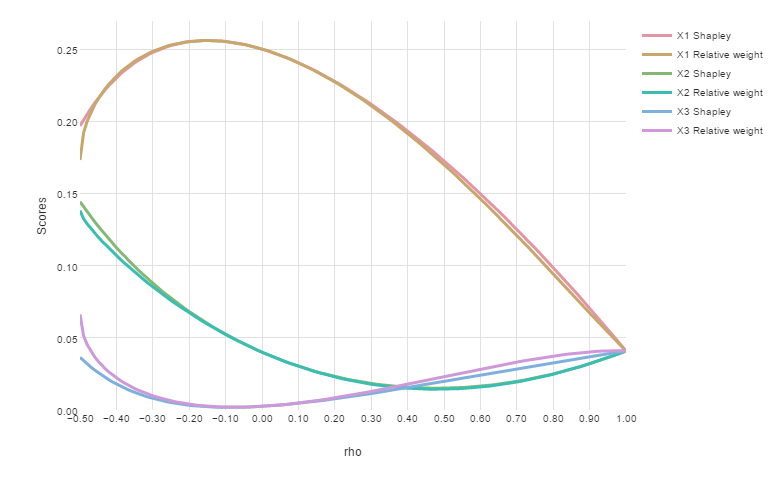
Shapley Regression Vs. Relative Weights | Understanding The Differences
Studies have shown that Shapley regression and Relative Weights provide surprisingly similar scores, despite being constructed in very different ways.
Continue reading