


Logistic regression, also known as binary logit and binary logistic regression, is a particularly useful predictive modeling technique, beloved in both the machine learning and the statistics communities. It is used to predict outcomes involving two options (e.g., buy versus not buy).
In this post I explain how to interpret the standard outputs from logistic regression, focusing on those that allow us to work out whether the model is good, and how it can be improved. These outputs are pretty standard and can be extracted from all the major data science and statistics tools (R, Python, Stata, SAS, SPSS, Displayr, Q). In this post I review prediction accuracy, pseudo r-squareds, AIC, the table of coefficients, and analysis of variance.
Create your own logistic regression
Prediction accuracy
The most basic diagnostic of a logistic regression is predictive accuracy. To understand this we need to look at the prediction-accuracy table (also known as the classification table, hit-miss table, and confusion matrix). The table below shows the prediction-accuracy table produced by Displayr’s logistic regression. At the base of the table you can see the percentage of correct predictions is 79.05%. This tells us that for the 3,522 observations (people) used in the model, the model correctly predicted whether or not somebody churned 79.05% of the time. Is this a good result? The answer depends a bit on context. In this case 79.05% is not quite as good as it might sound.
Starting with the No row of the table, we can see that the there were 2,301 people who did not churn and were correctly predicted not to have churned, whereas only 274 people who did not churn were predicted to have churned. If you hover your mouse over each of the cells of the table you see additional information, which computes a percentage telling us that the model accurately predicted non-churn for 83% of those that did not churn. So far so good.
Now, look at the second row. It shows us that among people who did churn, the model was only marginally more likely to predict they churned than did not churn (i.e., 483 versus 464). So, among people who did churn, the model only correctly predicts that they churned 51% of the time.
If you sum up the totals of the first row, you can see that 2,575 people did not churn. However, if you sum up the first column, you can see that the model has predicted that 2,765 people did not churn. What’s going on here? As most people did not churn, the model is able to get some easy wins by defaulting to predicting that people do not churn. There is nothing wrong with the model doing this. It is the optimal thing to do. But, it is important to keep this in mind when evaluating the accuracy of any predictive model. If the groups being predicted are not of equal size, the model can get away with just predicting people are in the larger category, so it is always important to check the accuracy separately for each of the groups being predicted (i.e., in this case, churners and non-churners). It is for this reason that you need to be sceptical when people try and impress you with the accuracy of predictive models; when predicting a rare outcome it is easy to have a model that predicts accurately (by making it always predict against the rare outcome).
Create your own logistic regression
Out-of-sample prediction accuracy
The accuracy discussed above is computed based on the same data that is used to fit the model. A more thorough way of assessing prediction accuracy is to perform the calculation using data not used to create the model. This tests whether the accuracy of the model is likely to hold up when used in the “real world”. The table below shows the prediction accuracy of the model when applied to 1,761 observations that were not used when fitting the logistic regression. The good news here is that in this case the prediction accuracy has improved a smidge to 79.1%. This is a bit of a fluke. Typically we would expect to see a lower prediction accuracy when assessed out-of-sample – often substantially lower.
Create your own logistic regression
R-squared and pseudo-r-squared
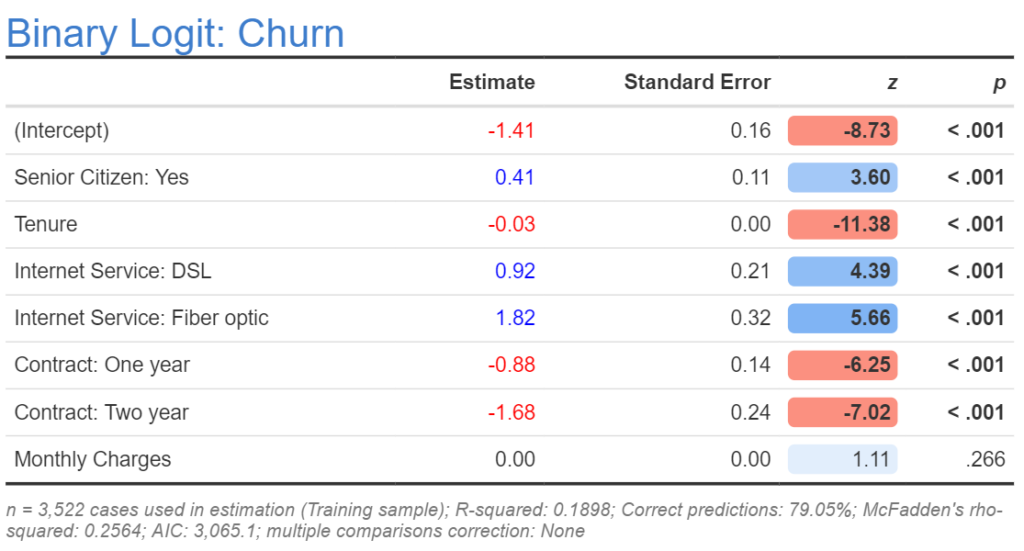
The footer of the table below shows that the r-squared for the model is 0.1898. This is interpreted in exactly the same way as with the r-squared in linear regression, and it tells us that this model only explains 19% of the variation in churning.
Although the r-squared is a valid computation for logistic regression, it is not widely used as there are a variety of situations where better models can have lower r-squared statistics. A variety of pseudo r-squared statistics are used instead. The footer for this table shows one of these, McFadden’s rho-squared. Like r-squared statistics, these statistics are guaranteed to take values from 0 to 1, where a higher value indicates a better model. The reason that they are preferred over traditional r-squared is that they are guaranteed to get higher as the fit of the model improves. The disadvantage of pseudo r-squared statistics is that they are only useful when compared to other models fit to the same data set (i.e., it is not possible to say if 0.2564 is a good value for McFadden’s rho-squared or not).
Create your own logistic regression
AIC
The Akaike information criterion (AIC) is a measure of the quality of the model and is shown at the bottom of the output above. This is one of the two best ways of comparing alternative logistic regressions (i.e., logistic regressions with different predictor variables). The way it is used is that all else being equal, the model with the lower AIC is superior. The AIC is generally better than pseudo r-squareds for comparing models, as it takes into account the complexity of the model (i.e., all else being equal, the AIC favors simpler models, whereas most pseudo r-squared statistics do not).
The AIC is also often better for comparing models than using out-of-sample predictive accuracy. Out-of-sample accuracy can be a quite insensitive and noisy metric. The AIC is less noisy because:
- There is no random component in it, whereas the out-of-sample predictive accuracy is sensitive to which data points were randomly selected for the estimation and validation (out-of-sample) data.
- It takes into account all of the probabilities. That is, when using out-of-sample predictive accuracy, both a 51% prediction and a 99% prediction have the same weight in the final calculation. By contrast, with the AIC, the 99% prediction leads to a lower AIC than the 51% prediction (i.e., the AIC takes into account the probabilities, rather than just the Yes or No prediction of the outcome variable).
The AIC is only useful for comparing relatively similar models. If comparing qualitatively different models, such as a logistic regression with a decision tree, or a very simple logistic regression with a complicated one, out-of-sample predictive accuracy is a better metric, as the AIC makes some strong assumptions regarding how to compare models, and the more different the models, the less robust these assumptions.
Create your own logistic regression
The table of coefficients
The table of coefficients from above has been repeated below. When making an initial check of a model it is usually most useful to look at the column called z, which shows the z-statistics. The way we read this is that the further a value is from 0, the stronger its role as a predictor. So, in this case we can see that the Tenure variable is the strongest predictor. The negative sign tells us that as tenure increases, the probability of churning decreases. We can also see that Monthly Charges is the weakest predictor, as its z is closest to 0. Further, the p-value for monthly charges is greater than the traditional cutoff of 0.05 (i.e, it is not “statistically significant”, to use the common albeit dodgy jargon). All the other predictors are “significant”. To get a more detailed understanding of how to read this table, we need to focus on the Estimate column, which I’ve gone to town on in How to Interpret Logistic Regression Coefficients.
Create your own logistic regression
Analysis of Variance (ANOVA)
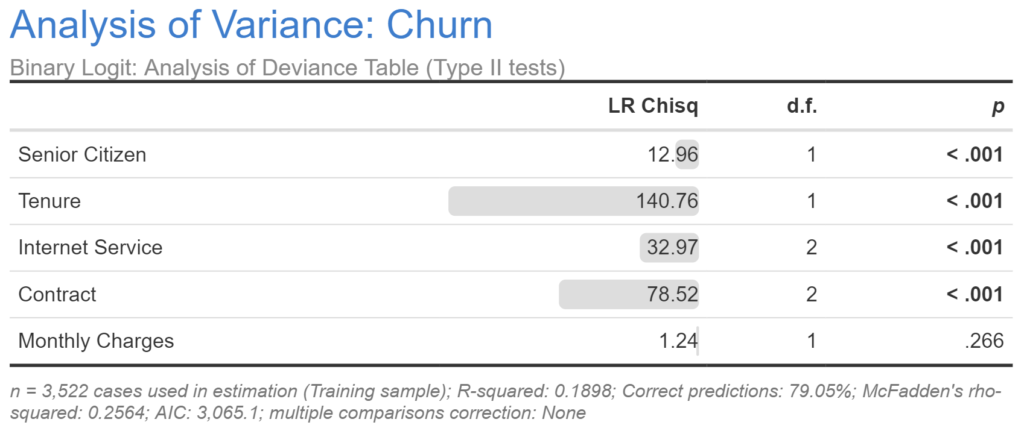
With logistic regressions involving categorical predictors, the table of coefficients can be difficult to interpret. In particular, when the model includes predictors with more than two categories, we have multiple estimates and p-values, and z-statistics. This is doubly problematic. First, it can be hard to get your head around how to interpret them. Second, sometimes some or all of the coefficients for a categorical predictor are not statistically significant, but for complicated reasons beyond the scope of this post it is possible to have none or some of the individual coefficients being significant, but for them all to be jointly significant (significant when assessed as a whole), and vice versa.
This problem is addressed by performing an analysis of variance (ANOVA) on the logistic regression. Sometimes these will be created as a separate table, as in the case of Displayr’s ANOVA table, shown below. In other cases the results will be integrated into the main table of coefficients (SPSS does this with its Wald tests). Typically, these will show either the results of a likelihood-ratio (LR) test or a Wald test.
The example below confirms that all the the predictors other than Monthly Charges are significant. We can also make some broad conclusions about relative importance by looking at the LR Chisq column, but when doing so keep in mind that with this statistic (and also with the Wald statistic shown by some other products, such as SPSS Statistics), that: (1) we cannot meaningfully compute ratios, so it is not the case that Tenure is almost twice as important as Contract; and, (2) the more categories in any of the predictors, the less valid these comparisons.
Create your own logistic regression
Other outputs
The outputs described above are the standard outputs, and will typically lead to the identification of key problems. However, they are by no means exhaustive, and there are many other more technical outputs that can be used which can lead to conclusions not detectable in these outputs. This is one of the ugly sides of building predictive models: there is always something more that can be checked, so you never can be 100% sure if your model is as good as it can be…
Now that you’ve improved your understanding of interpreting logistic regression outputs, start creating your own logistic regression in Displayr.