
How To Calculate Minimum Sample Size For A Survey Or Experiment

A practical question when designing a customer feedback survey or experiment is to work out the required sample size. That is, what is the smallest number of data points required in the survey or experiment? There are three basic approaches: rules of thumb based on industry standards, working backwards from budget, and working backwards from […]
5 Ways to Deal with Missing Data in Cluster Analysis
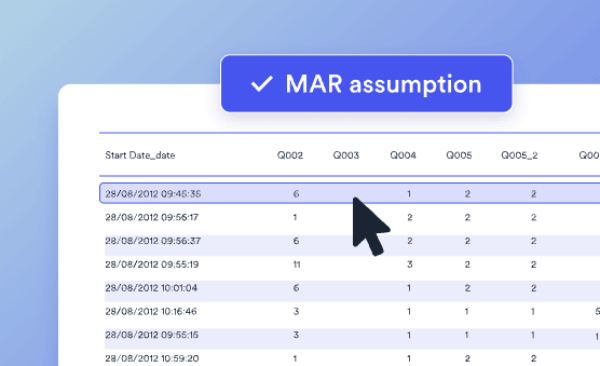
If you have ever tried to perform cluster analysis when you have missing data, there is a good chance your experience was ugly. Most cluster analysis algorithms ignore all of the data for cases with any missing data. Furthermore, best practice for dealing with missing data – multiple imputation – makes no sense when applied […]
Finding The Mean Of Categorical Data: Step-By-Step Guide

Traditionally, the primary statistic of interest for categorical data is the percentage of the cases in the data that fall into each category. However, there are a range of cases where it is useful to calculate an average value based on the categories. This requires that each category in the data be associated with a […]
How to Create a Color-Coded Word Cloud Using Sentiment Analysis (with Trump Tweets Example)
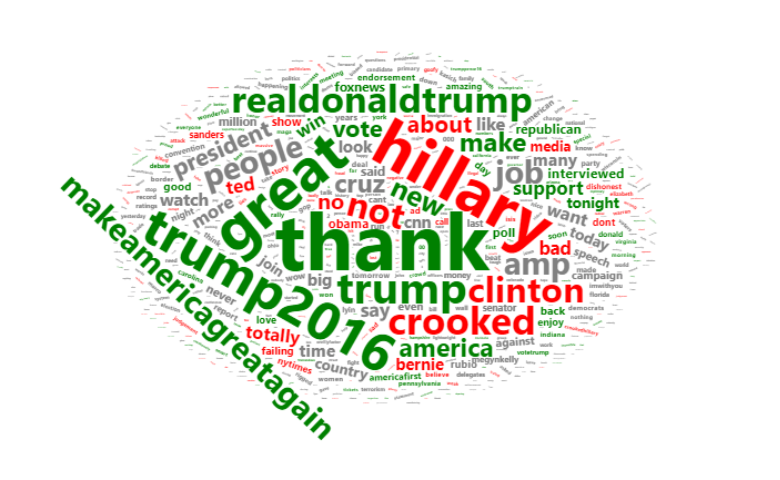
In this post, I describe how to create color-coded Word Cloud, where the colors are based on sentiment. Not only do you get to see which words are most prominent, but you get an idea of the tone with which they are used. The words in the Word Cloud are from tweets by President Trump. […]
The Magic Trick that Highlights Interesting Results on Any Table

This post describes the single biggest time saving technique that I know about for highlighting significant results on a table. The table below, which shows the results of a MANOVA, illustrates the trick. The coloring and bold fonts on the table quickly draw the eye to the two key patterns in the results: people aged 50 […]
Clustering with Missing Values: Why Latent Class Analysis Is The Way
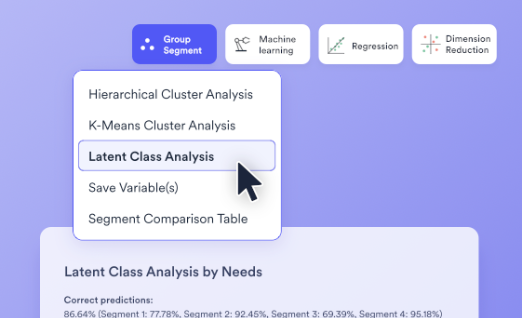
When it comes to segmenting your data, it’s not uncommon to deal with missing values. It might be because certain questions have not been asked in a survey or because of ‘don’t know’ responses that have come through in your data. Most of the widely used cluster analysis algorithms can be highly misleading or can […]
How to Analyze Free-Form Text Data from Surveys with AI

You want to give your survey respondents the opportunity to answer open-ended questions or elaborate on their responses. But how do you analyze the free-form text data from your survey? I’ll show you three different methods and explain when you might want to use each. What is Survey Text Analysis? Customer feedback surveys often allow […]
How to Enter Data from Paper Surveys

You’ve done it! You’ve collected data from 500 paper survey respondents and it’s all recorded onto paper forms. It’s time to start doing the analysis, but before you can create your report you need to get the data into a format that you can use in analysis software. Depending on your budget, perhaps the form […]
Automatic Data Checking: Let Your Analytics Package Do Your Dirty Laundry for You

Data checking is a bore (and a step we skip at our peril!). The laundry-list of data checking tasks can be seemingly endless: identifying bogus respondents, cleaning up the metadata, organizing the results. In larger organizations, data files may go through a special data-processing department before the researcher even sees it. In this scenario, the data checking and […]