


Selecting a choice model
The first step is to choose the method used to analyse the choice data. The choice is between latent class analysis, hierarchical Bayes or multinomial logit. Hierarchical Bayes is more flexible than latent class analysis in modeling the characteristics of each respondent in the survey, so it tends to produce a model that better fits the data. However, I would recommend latent class analysis when you want a segmentation of respondents. Multinomial logit, on the other hand, is equivalent to a single-class latent class analysis.
If you wish to run latent class analysis, select Insert > More > Conjoint/Choice Modeling > Latent Class Analysis. For hierarchical Bayes, select Insert > More > Conjoint/Choice Modeling > Hierarchical Bayes. A new R output called choice.model will appear in the Report tree on the left, with the following controls in the object inspector form on the right (this one is for latent class analysis).
Inputting the design
The next step is to specify the choice experimental design at the Design source control. There are six options:
1. Data set: specify the design through variables in the data set. Variables need to be supplied corresponding to the version, task and attribute columns of a design. See here for an example.
2. Experimental design R output: supply the design through a choice model design R output in the project (created using Automate > Browse Online Library > Conjoint/Choice Modeling > Experimental Design).
3. Sawtooth CHO format: supply the design using a Sawtooth CHO file. You’ll need to upload the CHO file to the project as a data set (first rename it to end in .txt instead of .cho so that it can be recognised by Displayr). The new data set will contain a text variable, which should be supplied to the CHO file text variable control.
4. Sawtooth dual file format: supply the design through a Sawtooth design file (from the Sawtooth dual file format). You’ll need to upload this file to the project as a data set. The version, task and attributes from the design should be supplied to the corresponding controls (similar to the Data set option).
5. JMP format: supply the design through a JMP design file. You’ll need to upload this file to the project as a data set. The version, task and attributes from the design should be supplied to the corresponding controls (similar to the Data set option).
6. Experiment variable set: supply the design through an Experiment variable set in the project.
For most of these options, you’ll also need to provide attribute levels through a spreadsheet-style data editor. This is optional for the JMP format if the design file already contains attribute level names. The levels are supplied in columns, with the attribute name in the first row and attribute levels in subsequent rows.
Inputting the respondent data
Whether respondent data needs to be explicitly provided depends on how you supplied the design in the previous step. If an Experiment Question or CHO file was provided, there is no need to separately provide the data, as Experiment Questions and CHO files already contain the choices made by the respondents.
With the other ways of supplying the design, the respondent choices and the task numbers corresponding to these choices need to be provided from variables in the project. Each variable corresponds to a question in the choice experiment and the variables need to be provided in the same order as the questions.
If your conjoint data comes from Alchemer (formerly SurveyGizmo), you will need to first add both the conjoint and respondent data files as data sets and go to Insert > Conjoint/Choice Modeling > Convert Alchemer (Survey Gizmo) Conjoint Data for Analysis. Displayr will then add the appropriate questions containing the choices and the design version in the respondent data set.
Instead of using respondent data, there is also an option to use simulated data, by changing the Data source setting to Simulated choices from priors. Please see this blog post for more information on using simulated data.
If there are missing responses in the data, the default setting in the Missing data control is Use partial data. This means that Displayr has removed questions with missing data, but has kept other questions for analysis. Alternatively, Exclude cases with missing data removes any respondents with missing data, and Error if missing data shows an error message if any missing data is present.
Model settings
The final step is to specify the model settings. There is an option to choose between Latent class analysis or Hierarchical Bayes, so that even though you chose one at the start when creating the output, you can always switch to the other later. If you’ve chosen latent class analysis, there is an option to set the number of latent classes and also the number of questions per respondent to leave out for cross-validation.
The more latent classes in the model, the more flexible it is at fitting to the data. However, if there are too many classes, computation time will be long, and the model may be over-fit to the data. To determine the amount of overfitting in the data, you should set Questions left out for cross-validation to be greater than the default of 0. This means that you’ll be able to compare in-sample and out-of-sample prediction accuracies in the output.
There is a checkbox which controls whether alternative-specific constants are added to the model. They are included by default, in order to capture any alternative-specific bias in respondents.
If you’ve picked hierarchical Bayes, you’ll have some more options. This is covered in How to Use Hierarchical Bayes for Choice Modeling in Displayr so I won’t go over them here. This may take a few seconds to run or much longer depending on the model specifications and the size of the data.
Filters and Weights
You can apply filters and weights to the output via the object inspector, except for hierarchical Bayes, where you cannot apply weights.
Interpreting the output
Shown below is a screenshot from Displayr of a typical choice model output from a choice experiment on egg preferences. At the top is the title and a subtitle showing the prediction accuracy (out-of-sample accuracy if questions are left out). In the rows of the table are the parameters of the model, which correspond to the attribute levels for categorical attributes, or the attributes themselves for numeric attributes. For each parameter, Displayr shows a histogram indicating the distribution of its coefficients amongst the respondents. The bars in the histogram are blue and red for positive and negative values respectively.
The last two columns show the mean and standard deviation of the values, where a larger magnitude of the mean generally indicates that a parameter is more important, and a larger standard deviation indicates more variation in preference for the parameter’s attribute level. In the example below, the price parameter is completely negative since a high price is worse than a low price, all else being equal. However, there is considerable variation amongst respondents in the value, reflecting differing sensitivities to price.
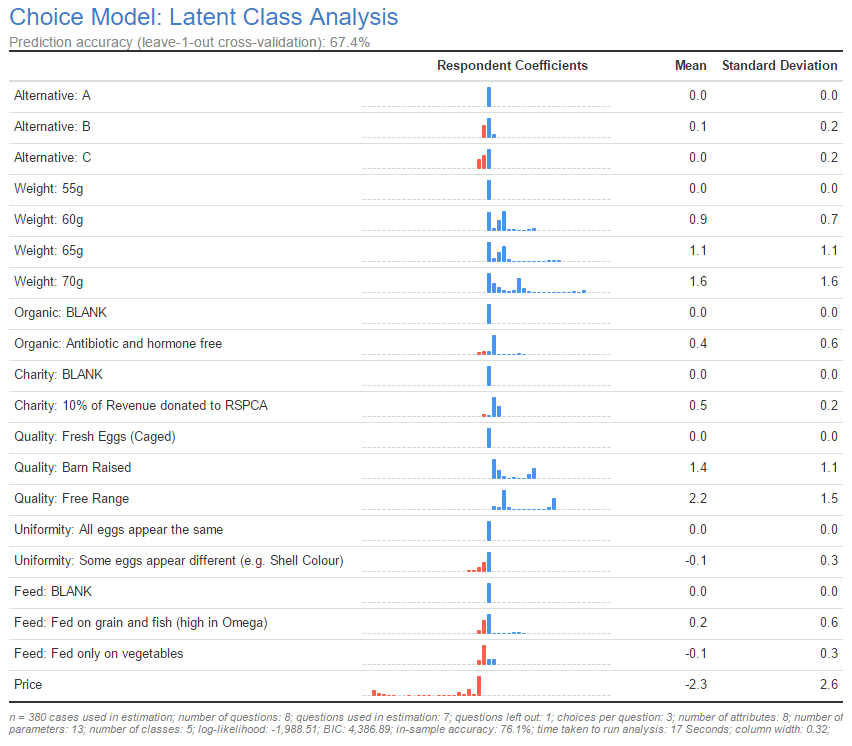
The footer at the bottom of the output contains information about the choice experiment data used in the model and some results from the model such as the log-likelihood and BIC. You can use this for comparison against other model outputs (provided the input data is the same). The in-sample accuracy is shown in the footer when questions are left out for cross-validation, and you should compare it against the out-of-sample accuracy in the subtitle.
Extra features for choice modeling
I have described the process of setting up and running a choice model in Displayr, but there are still many things that can be done with the choice model output, which are found in the Insert > More > Conjoint/Choice Modeling menu. For example, you can compare and combine outputs into an ensemble model using Compare Models and Ensemble of Models. Diagnostics can be run on the output by highlighting the output and selecting an item from the Insert > More > Conjoint/Choice Modeling > Diagnostics menu, to produce information such as parameter statistics which indicate if there were any issues with parameter estimation. In addition, variables containing respondent coefficients and respondent class memberships can be produced for the output through the Insert > More > Conjoint/Choice Modeling > Save Variable(s) menu.
To explore a Displayr document containing an example of a latent class analysis and a hierarchical Bayes output, click here. Alternatively, create your own latent class or hierarchical Bayes analysis for free!
