
Machine Learning.

Learn how variable importance is calculated in random forests using both accuracy-based and Gini-based measures.
Continue reading
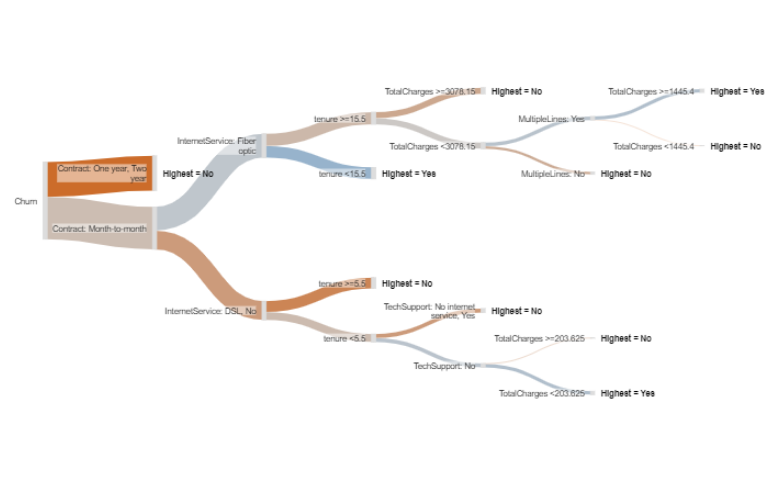
Logistic regression is a standard approach to building a predictive model. However, decision trees are an alternative which are clearer and often superior.
Continue reading

There are two types of predictors in predictive models: numeric and categorical. There are several methods of transforming categorical variables.
Continue reading

When building a predictive model, it is often practical to improve predictive performance by modifying the numeric variables. This is called transformation.
Continue reading

A random forest is a collection of decision trees, which is used to learn patterns in data and make predictions based on those patterns.
Continue reading

Decision trees work by repeatedly splitting the data to lead to the option which causes the greatest improvement. We explain how these splits are chosen.
Continue reading

Machine learning is an issue of trade-offs. Here we look at pruning and other ways of managing these trade-offs in the context of decision trees. Read more.
Continue reading