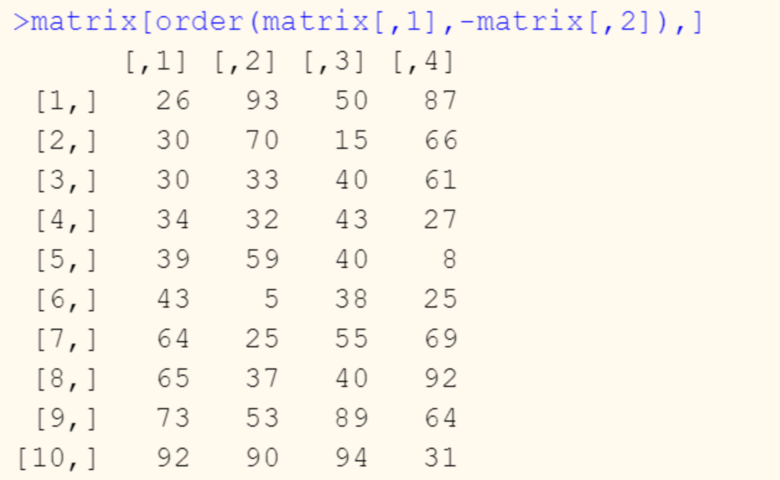
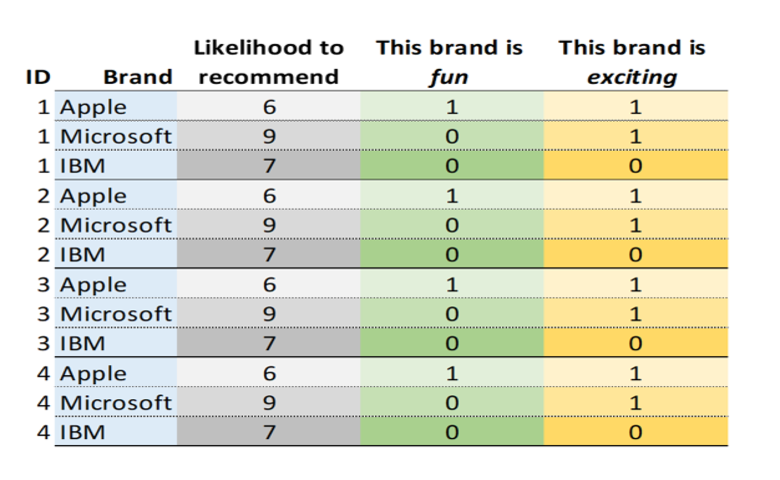
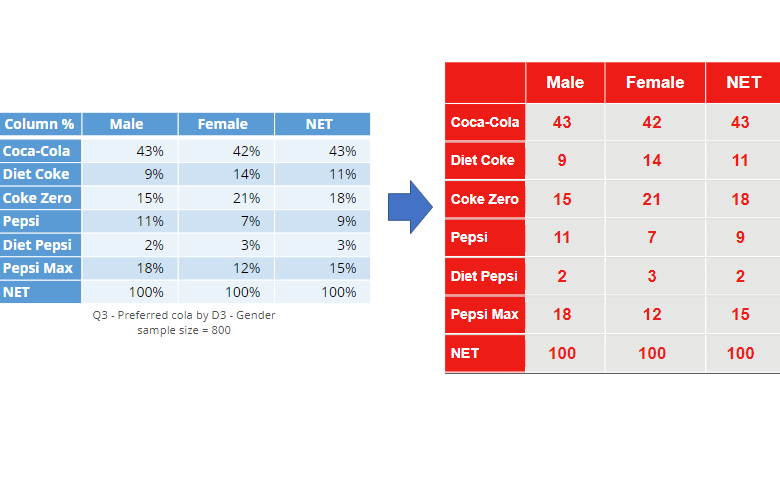
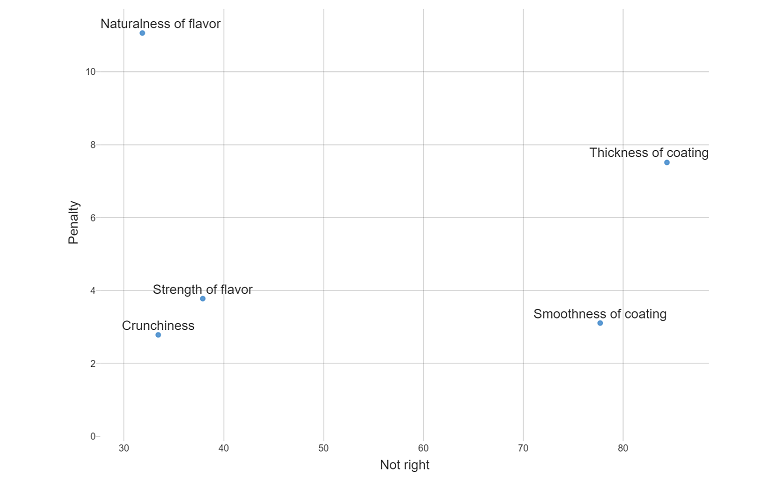
R for Data Science.
Dive into all things R, Data Science, and Displayr, with how-to guides, video explainers, and pro tips. Whether you’re a beginner or an experienced data scientist, our resources cover everything from basic data manipulation to text analytics, all using R. Unlock the power of R and see how you can use it to unlock unlimited flexibility in your data analysis.
R Resources: